КОНСПЕКТ ЛЕКЦИЙ ПО КУРСУ ОПЕРАЦИОННЫЕ
СИСТЕМЫ
1.
Основные понятия и определения.
5.
Принципы построения и классификация
6.
Защита от сбоев и несанкционированного доступа
1. Основные
понятия и определения.
1.1.
Назначение и функции операционных систем.
Операционная система — это программа, контролирующая работу пользовательской программы и систем приложений и исполняемая роль интерфейса между приложениями и аппаратным обеспечением компьютера. Её предназначения можно разделить на три основные составляющие:
· удобство: операционная система делает исполнение компьютера простым и удобным
· эффективность: операционная система позволяет эффективно использовать ресурсы компьютерной системы
· возможность развития: операционная система должна допускать разработку тестирования новых приложений и системных функций без нарушения нормального функционирования вычислительной системы.
Согласно многолетней традиции, при рассмотрении основ функционирования ОС
принято выделять четыре основных группы функций, выполняемых системой.
Управление устройствами. Имеются в виду все периферийные устройства,
подключаемые к компьютеру, — клавиатура, монитор, принтеры, диски и т.п.
Управление данными. Под этим старинным термином сейчас понимается работа с
файлами, хотя были времена, когда обращение к данным на магнитных носителях
выполнялось путем указания адреса размещения данных на устройстве, а понятия
файла не существовало.
Управление процессами. Эта сторона работы ОС связана с запуском и завершением
работы программ, обработкой ошибок, обеспечением параллельной работы нескольких
программ на одном компьютере.
Управление памятью. Оперативная память компьютера — это такой ресурс, которого
всегда не хватает. В этих условиях разумное планирование использования памяти
является важнейшим фактором эффективной работы.
Имеется еще несколько важных обязанностей, ложащихся на ОС, которые трудно
втиснуть в рамки традиционной классификации функций. К ним, прежде всего,
относятся следующие.
Организация интерфейса с пользователем. Формы интерфейса могут быть
разнообразными, в зависимости от типа и назначения ОС: язык управления пакетами
заданий, набор диалоговых команд, средства графического интерфейса.
Защита данных. Как только система перестает быть достоянием одного
изолированного от внешнего мира пользователя, вопросы защиты данных от
несанкционированного доступа приобретают первостепенную важность. ОС,
обеспечивающая работу в сети или в системе разделения времени, должна
соответствовать имеющимся стандартам безопасности.
Ведение статистики. В ходе работы ОС должна собираться, храниться и
анализироваться разнообразная информация: о количестве времени, затраченном
различными программами и пользователями, об интенсивности использования
ресурсов, о попытках некорректных действий пользователей, о сбоях оборудования
и т.п. Собранная информация хранится в системных журналах и в учетных записях
пользователей.
1.2. Операционная среда
Операционная система выполняет функции управления вычислительными процессами в вычислительной системе, распределяет ресурсы вычислительной системы между различными вычислительными процессами и образует программную среду, в которой выполняются прикладные программы пользователя. Такая среда называется операционной.
Любая программа имеет дело с некоторыми исходными данными, которые она обрабатывает и порождает некоторые выходные данные, т.е. результаты вычислений. В абсолютном большинстве случаев исходные данные попадают в оперативную память внешних периферийных устройств.
Результаты вычислений также выводятся на внешние устройства. Программирование операций вводавывода является наиболее сложной задачей. Именно поэтому развитие операционной системы пошло по пути выделения наиболее часто встречающихся операций и создании для них соответствующих модулей, которые можно в дальнейшем использовать во вновь создаваемых программах. В конечном итоге возникла ситуация, когда при создании двоичных машинных программ …
Программисты могут вообще не знать многих деталей управления ресурсами вычислительной системы, а должны обращаться к некоторой программной подсистеме с соответствующими выводами и получить необходимые функции сервиса. Эта программная подсистема и есть операционная система, а набор её функций сервиса и привело обращение к ней и образует базовое понятие, которое называется операционной средой, т.е. термин операционная среда означает необходимые интерфейсные программы пользователя для обращения к операционной системе с целью получить определённый сервис. Параллельное существование терминов операционная система и операционная среда вызвано тем, что операционная система может поддержать несколько операционных сред.
1.3. Прерывания
Прерывания аппаратные — это сигналы, при поступлении которых нормальная последовательность выполнения программы может быть прервана, при этом система запоминает информацию, необходимую для возобновления работы прерванной программы, и передает управление подпрограмме обработки прерывания ISR, Interrupt Service Routine. По завершению обработки, как правило, управление возвращается прерванной программе.
Все прерывания можно разделить на три основных типа:
1. аппаратные прерывания от периферийных устройств
2. внутренние аппаратные прерывания называемые также исключениями, exceptions
3. программные прерывания.
В подавляющем большинстве ОС обработку всех прерываний берет на себя сама система, поскольку это слишком интимная часть работы, способная повлиять на функционирование всех системных и прикладных программ.
Поскольку типы и разновидности прерываний весьма многообразны и каждый из них требует особой обработки, большинство процессоров поддерживает векторные прерывания. Это означает, что каждая разновидность прерывания имеет свой номер, и этот номер используется как индекс в массиве, хранящем адреса ISR для всех прерываний. При возникновении прерывания аппаратура компьютера по номеру прерывания определяет адрес подпрограммы обработки и вызывает ее.
Для того чтобы некоторые наиболее ответственные участки системных программ выполнялись без прерываний, система имеет возможность временно запретить прием большинства прерываний. Такой запрет должен устанавливаться лишь на короткие интервалы времени, не более нескольких миллисекунд.
Программные прерывания вызываются выполнением специальной команды, но обрабатываются точно так же, как остальные типы прерываний. По сути, команда программного прерывания представляет собой особый случай вызова подпрограммы, но при этом вместо адреса подпрограммы указывается номер прерывания, обработчик которого должен быть вызван. В большинстве современных ОС программные прерывания используются для перехода из режима пользователя в режим ядра при вызове системных функций из прикладной программы.
Одним из важнейших источников прерываний являются периферийные устройства. Как правило, устройство генерирует сигнал прерывания в одном из двух случаев:
· при переходе в состояние готовности
· при возникновении ошибки выполнения операции.
Состояние готовности — это такое состояние устройства, в котором оно готово принять и выполнить команды от процессора. Для устройства ввода готовность означает наличие в устройстве данных, которые могут быть переданы в процессор например, клавиатура переходит в состояние Готово при нажатии клавиши и возвращается в состояние Не готово, когда код нажатой клавиши считан в процессор. Для устройства вывода готовность — это возможность принять от процессора данные, которые следует вывести. Например, матричный принтер принимает символы, которые нужно напечатать, в свой внутренний буфер. Если буфер полон, принтер переходит в состояние Не готово до тех пор, пока часть символов будет напечатана и в буфере освободится место. Дисковый накопитель при начале выполнения новой операции чтения или записи на диск переходит в состояние Не готово, а после завершения операции возвращается в состояние Готово. В любом из этих случаев переход в состояние Готово — это повод для устройства напомнить о себе процессору: обратите на меня внимание, я к вашим услугам! Для этого и служит сигнал прерывания.
Ошибка операции также требует вмешательства системы или пользователя. Например, при ошибке отсутствия бумаги в лотке принтера система должна оповестить об этом пользователя; при ошибке чтения с диска либо система, либо пользователь должен решить, что делать: повторить операцию, завершить программу или продолжить выполнение.
Не каждое устройство генерирует прерывания. Например, монитор ПК не выдает прерываний: он всегда готов, т.е. всегда может принять данные для отображения, и он никогда не ошибается, точнее сказать, его неисправность обнаруживается на глаз.
1.4. Процессы и потоки
В операционных системах, где существуют и процессы, и потоки, процесс рассматривается операционной системой как заявка на потребление всех видов ресурсов, кроме одного — процессорного времени. Этот последний важнейший ресурс распределяется операционной системой между другими единицами работы — потоками, которые и получили свое название благодаря тому, что они представляют собой последовательности потоки выполнения команд.
В простейшем случае процесс состоит из одного потока, и именно таким образом трактовалось понятие процесс до середины 80-х годов например, в ранних версиях UNIX и в таком же виде оно сохранилось в некоторых современных ОС. В таких системах понятие поток полностью поглощается понятием процесс, то есть остается только одна единица работы и потребления ресурсов — процесс. Мультипрограммирование осуществляется в таких ОС на уровне процессов.
Для того чтобы процессы не могли вмешаться в распределение ресурсов, а также не могли повредить коды и данные друг друга, важнейшей задачей ОС является изоляция одного процесса от другого. Для этого операционная система обеспечивает каждый процесс отдельным виртуальным адресным пространством, так что ни один процесс не может получить прямого доступа к командам и данным другого процесса.
При необходимости взаимодействия процессы обращаются к операционной системе, которая, выполняя функции посредника, предоставляет им средства межпроцессной связи — конвейеры, почтовые ящики, разделяемые секции памяти и некоторые другие.
Однако в системах, в которых отсутствует понятие потока, возникают проблемы при организации параллельных вычислений в рамках процесса. А такая необходимость может возникать. Действительно, при мультипрограммировании повышается пропускная способность системы, но отдельный процесс никогда не может быть выполнен быстрее, чем в однопрограммном режиме всякое разделение ресурсов только замедляет работу одного из участников за счет дополнительных затрат времени на ожидание освобождения ресурса.
Потоки возникли в операционных системах как средство распараллеливания вычислений. Конечно, задача распараллеливания вычислений в рамках одного приложения может быть решена и традиционными способами.
1.5. Файлы и файловые системы
Старинный термин управление данными в настоящее время всегда понимается как управление файлами.
Файл есть набор данных, хранящийся на периферийном устройстве и доступный по имени. При этом конкретное расположение данных на устройстве не интересует пользователя и полностью передоверяется системе. До изобретения файлов пользователь должен был обращаться к своим данным, указывая их адреса на диске или на магнитной ленте.
Понятие файловая система означает стандартизованную совокупность структур данных, алгоритмов и программ, обеспечивающих хранение файлов и выполнение операций с ними. Мощная современная ОС обычно поддерживает возможность использования нескольких разных файловых систем. И наоборот, одна и та же файловая система может поддерживаться различными ОС.
Среди задач, решаемых подсистемой управления данными, можно назвать
следующие:
выполнение операций создания, удаления, переименования, поиска файлов, чтения и
записи данных в файлы, а также ряда вспомогательных операций
· обеспечение эффективного использования дискового пространства и высокой скорости доступа к данным
· обеспечение надежности хранения данных и их восстановления в случае сбоев
· защита данных пользователя от несанкционированного доступа
· управление одновременным совместным использованием данных со стороны нескольких процессов.
1.6. Память
Основная память она же ОЗУ является важнейшим ресурсом, эффективное использование которого решающим образом влияет на общую производительность системы.
Для однозадачных ОС управление памятью не является серьезной проблемой,
поскольку вся память, не занятая системой под собственные нужды, может быть
отдана в распоряжение единственного пользовательского процесса. Процедуры
управления памятью решают следующие задачи:
выделение памяти для процесса пользователя при его запуске и освобождение этой
памяти при завершении процесса
обеспечение настройки запускаемой программы на выделенные адреса памяти
управление выделенными областями памяти по запросам программы пользователя например, освобождение части памяти перед запуском порожденного процесса.
Совершенно иначе обстоят дела в многозадачных ОС. Суммарные требования к объему памяти всех одновременно работающих в системе программ, как правило, превышают имеющийся в наличии объем основной памяти. В этих условиях ОС не имеет другого выхода, кроме поочередного вытеснения процессов или их частей на диск, чтобы использовать освободившуюся память на нужды других процессов. Неудачная реализация такого вытеснения может почти полностью застопорить работу ОС, которая большую часть времени будет заниматься записью и чтением с диска.
К основным задачам, которые должна решать подсистема управления памятью
многозадачной ОС, добавляются следующие.
предоставление процессам возможностей получения и освобождения дополнительных
областей памяти в ходе работы
эффективное использование ограниченного объема основной памяти для удовлетворения нужд всех работающих процессов, в том числе с использованием дисков как расширения памяти
изоляция памяти процессов, исключающая случайное или намеренное несанкционированное обращение одного процесса к областям памяти, занимаемым другим процессом
предоставление процессам возможности обмена данными через общие области памяти.
1.7. Пользователи
Пользователь — в программировании — лицо или организация, т.е. абонент.
Он использует данную программу для выполнения конкретной функции на основании пользовательского соглашения.
Пользователь обязан выполнять пользовательское соглашение для обеспечения компьютерной, информационной безопасности. Пользователем является только человек, физическое лицо или организация, юридическое лицо.. Пользователем является человек, использующий компьютер, программу либо сеть для решения стоящих перед ним задач. Его именуют иногда конечный потребитель, конечным пользователем программного продукта.
1.8. Режимы работы
Мультипрограммирование — это режим обработки данных, при котором ресурсы вычислительной системы предоставляются каждому процессу из группы процессов обработки данных, находящихся в ВС, на интервалы времени, длительность и очередность предоставления которых определяется управляющей программой этой системы с целью обеспечения одновременной работы в интерактивном режиме.
Режим реального времени — режим обработки данных, при котором обеспечивается взаимодействие вычислительной системы с внешними по отношению к ней процессами в темпе, соизмеримом со скоростью протекания этих процессов. Этот режим обработки данных широко используется в системах управления и информационно-поисковых системах.
В однопрограммном режиме работы в памяти ЭВМ находится и выполняется только одна программ. Такой режим обычно характерен для микро-ЭВМ и персональных ЭВМ, то есть для ЭВМ индивидуального пользования.
В мультипрограммном многопрограммном режиме работы в памяти ЭВМ находится несколько программ, которые выполняются частично или полностью между переходами процессора от одной задачи к другой в зависимости от ситуации, складывающейся в системе. В мультипрограммном режиме более эффективно используются машинное время и оперативная память, так как при возникновении каких-либо ситуаций в выполняемой задаче, требующих перехода процессора в режим ожидания, процессор переключается на другую задачу и выполняет ее до тех пор, пока в ней не возникает подобная ситуация, и т.д. При реализации мультипрограммного режима требуется определять очередность переключения задач и выбирать моменты переключения, чтобы эффективность использования машинного времени и памяти была максимальной. Мультипрограммный режим обеспечивается аппаратными средствами ЭВМ и средствами операционной системы. Он характерен для сложных ЭВМ, где стоимость машинного времени значительно выше, чем у микро-ЭВМ. Разработаны также мультипрограммные ОС, позволяющие одновременно следить за решением нескольких задач и повышать эффективность работы пользователя.
В зависимости от того, в каком порядке при мультипрограммном режиме выполняются программы пользователей, различают режимы пакетной обработки задач и коллективного доступа.
В режиме пакетной обработки задачи выстраиваются в одну или несколько очередей и последовательно выбираются для их выполнения.
В режиме коллективного доступа каждый пользователь ставит свою задачу на выполнение в любой момент времени, то есть для каждого пользователя в такой ВС реализуется режим индивидуального пользования. Это осуществляется обычно с помощью квантования машинного времени, когда каждой задаче, находящейся в оперативной памяти ЭВМ, выделяется квант времени. После окончания кванта времени процессор переключается на другую задачу или продолжает выполнение прерванной в зависимости от ситуации в ВС. Вычислительные системы, обеспечивающие коллективный доступ пользователей с квантованием машинного времени, называют ВС с разделением времени.
2.
Управление процессами
2.1. Концепция процесса
Процесс — это система действий, реализующая определенную функцию в вычислительной системе и оформленная так, что управляющая программа вычислительной системы может перераспределять ресурсы этой системы в целях обеспечения мультипрограммирования.
Понятие процесса тесно связано с понятием задача:
Задача — в режиме мультипрограммирования или мультипроцессорной обработки одна или более последовательностей команд, обрабатываемых управляющей программой как элемент работы, которая выполняется вычислительной машиной.
Выполнение задачи реализуется в вычислительной системе запуском не менее
одного процесса. Можно говорить, что задача — это один или несколько процессов,
обеспечивающих достижение поставленных пользователем целей.
Следует отличать понятия процесс и задача от понятий программа и задание.
Программа для ЭВМ — упорядоченная последовательность команд, подлежащих обработке.
Задание вычислительной системе — единица работы, возлагаемой на вычислительную систему пользователем, оформленная для ввода в вычислительную систему независимо от других таких же единиц.
Отношение программы и задания аналогично отношению процесса и задачи, т.е. каждое задание содержит не менее одной программы, предназначенной для обработки в ЭВМ.
Об отношении процесса и программы можно сказать, что процесс — это программа во время ее выполнения. Всякая программа становится процессом, когда начинает выполняться в ЭВМ.
В период своего существования процесс может находиться в одном из следующих основных состояний:
· порождение, во время которого подготавливаются условия для первого исполнения на центральном процессоре
· активное состояние выполнение, когда процессу принадлежит центральный процессор
· ожидание, во время которого процесс блокирован по причине занятости каких-либо необходимых ему ресурсов
· готовность, при котором процесс получил все необходимые ему ресурсы, кроме центрального процессора
· окончание, во время которого выполняются завершающие работу операции, после чего ресурсы процессу больше не предоставляются.
2.2. Идентификатор, дескриптор и контекст процессов.
Каждый процесс в операционной системе получает уникальный идентификационный номер — PID process identificator. При создании нового процесса операционная система пытается присвоить ему свободный номер больший, чем у процесса, созданного перед ним. Если таких свободных номеров не оказывается например, мы достигли максимально возможного номера для процесса, то операционная система выбирает минимальный номер из всех свободных номеров.
Дескриптор процесса включает в себя все те данные о процессе, которые могут понадобиться ОС при различных состояниях процесса. В число элементов дескриптора могут входить, например, идентификатор процесса некое условное число, обозначающее данный процесс; текущее состояние процесса; его приоритет; владелец процесса т.е. идентификатор пользователя, запустившего процесс; статистика затраченного процессом общего и процессорного времени; указатель местоположения контекста процесса и др. Дескрипторы всех процессов, существующих в системе, собраны в таблицу процессов.
Контекст процесса включает данные, необходимые только для текущего процесса. Суда относятся, прежде всего, значения всех регистров процессора, включая указатель текущей команды; таблица файлов, открытых процессом; указатели на области памяти, которые должен занимать процесс при его выполнении; значения системных переменных, используемых процессом например, текущий диск и каталог, информация о последней ошибке при выполнении системных функций; другие системные флаги и режимы, которые могут иметь разные значения для разных процессов. Точный состав дескриптора и контекста сильно зависят от конкретной ОС.
2.3. Иерархия процессов
В некоторых системах, когда процесс порождает другой процесс, родительский и дочерний процессы продолжают быть определенным образом связанными друг с другом. Дочерний процесс может и сам создавать какие-нибудь процессы, формируя иерахию процессов.
2.4. Диспетчеризация процессов
Диспетчеризация процессов задач — это определение очерёдности получения процессора для процессов задач, находящихся в состоянии готовности, с целью их выполнения. Диспетчеризация процесса связана с его переводом из состояния готовности в состояние выполнения счёта. Диспетчеризация, для конкретного процесса, может выполняться многократно, т. е. процесс может несколько раз переходить из состояния готовности в состояние выполнения и обратно на интервале своего существования. Так как в каждый такт процессорного времени могут выполняться команды только одной задачи, диспетчеризация предполагает создание и модификацию очереди готовых к выполнению задач процессов. Элементами такой очереди как и других очередей в вычислительной системе на физическом уровне являются дескрипторы задач.
2.5. Понятие приоритета и очереди процессов
Приоритет — свойство процесса, определяющее важность необходимость выполнения.
Назначение приоритетов выполняется пользователем либо администратором
системы, возможно также программное изменение приоритета процесса. На выбор
оптимального уровня приоритета влияют в основном два соображения:
важность, ответственность данного процесса либо привилегированное положение
запускающего процесс пользователя
количество процессорного времени, на которое будет претендовать процесс как мы видели в примере с фоновой печатью, высокий приоритет процесса, мало загружающего процессор, почти не приводит к замедлению работы остальных процессов.
Основной алгоритм приоритетного планирования напоминает простое круговое планирование, однако круговая очередь активных процессов формируется отдельно для каждого уровня приоритета. Пока есть хоть один активный процесс в очереди с самым высоким приоритетом, процессы с более низкими приоритетами не могут получить управление. Только когда все процессы с высшим приоритетом заблокированы либо завершены, планировщик выбирает процесс из очереди с более низким приоритетом.
Приоритет, присваиваемый процессу при создании, называется статическим приоритетом. Дисциплина планирования, использующая только статические приоритеты, имеет один существенный недостаток: низкоприоритетные процессы могут надолго оказаться полностью отлученными от процессора. Иногда это приемлемо если высокоприоритетные процессы несравнимо важнее, чем низкоприоритетные, однако чаще хотелось бы, чтобы и на низкие приоритеты хоть что-нибудь перепадало, пусть даже реже и в меньшем количестве, чем на высокие. Для решения этой задачи предложено множество разных алгоритмов планирования процессов, основанных на идее динамического приоритета.
2.6. Синхронизация процессов
Синхронизация процессов — приведение двух или нескольких процессов к такому их протеканию, когда определённые стадии разных процессов совершаются в определённом порядке, либо одновременно.
Синхронизация необходима в любых случаях, когда параллельно протекающим процессам необходимо взаимодействовать. Для её организации используются средства межпроцессного взаимодействия. Среди наиболее часто используемых средств — сигналы и сообщения, семафоры и мьютексы, каналы англ. pipe, совместно используемая память.
2.7. Средства обработки сигналов
Сигналы представляют собой средство уведомления процесса о наступлении некоторого события в системе. Инициатором посылки сигнала может выступать как другой процесс, так и сама ОС. Сигналы, посылаемые ОС, уведомляют о наступлении некоторых строго предопределенных ситуаций. при этом каждой такой ситуации сопоставлен свой сигнал. Кроме того, зарезервирован один или несколько номеров сигналов, семантика которых определяется пользовательскими процессами по своему усмотрению.
Сигналы являются механизмом асинхронного взаимодействия, т.е. момент прихода сигнала процессу заранее неизвестен. Однако, процесс может предвидеть возможность получения того или иного сигнала и установить определенную реакцию на его приход. В этом плане сигналы можно рассматривать как программный аналог аппаратных прерываний.
При получении сигнала процессом возможны три варианта реакции на полученный
сигнал:
Процесс реагирует на сигнал стандартным образом, установленным по умолчанию для
большинства сигналов действие по умолчанию — это завершение процесса
Процесс может установить специальную обработку сигнала, в этом случае по
приходу сигнала вызывается функция-обработчик, определенная процессом при этом
говорят, что сигнал перехватывается
Процесс может проигнорировать сигнал
Для каждого сигнала процесс может устанавливать свой вариант реакции, например, некоторые сигналы он может игнорировать, некоторые перехватывать, а на остальные установить реакцию по умолчанию. При этом в процессе своей работы процесс может изменять вариант реакции на тот или иной сигнал. Однако, необходимо отметить, что некоторые сигналы невозможно ни перехватить, ни игнорировать. Они используются ядром ОС для управления работой процессов
Если в процесс одновременно доставляется несколько различных сигналов, то порядок их обработки не определен. Если же обработки ждут несколько экземпляров одного и того же сигнала, то ответ на вопрос, сколько экземпляров будет доставлено в процесс — все или один — зависит от конкретной реализации ОС.
2.8. Понятие событийного программирования
Событийно-ориентированное программирование — парадигма программирования, в которой выполнение программы определяется событиями — действиями пользователя клавиатура, мышь, сообщениями других программ и потоков, событиями операционной системы например, поступлением сетевого пакета.
СОП можно также определить как способ построения компьютерной программы, при
котором в коде как правило, в головной функции программы явным образом
выделяется главный цикл приложения, тело которого состоит из двух частей:
выборки события и обработки события.
Как правило, в реальных задачах оказывается недопустимым длительное выполнение
обработчика события, поскольку при этом программа не может реагировать на
другие события. В связи с этим при написании событийно-ориентированных программ
часто применяют автоматное программирование.
2.9. Средства коммуникации процессов
Одна из важнейших целей, которые ставятся при разработке многозадачных систем, заключается в том, чтобы разные процессы, одновременно работающие в системе, были как можно лучше изолированы друг от друга. Это означает, что процессы в идеале не должны ничего знать даже о существовании друг друга. Для каждого процесса ОС предоставляет виртуальную машину, т.е. полный набор ресурсов, имитирующий выполнение процесса на отдельном компьютере.
Изоляция процессов, во-первых, является необходимым условием надежности и безопасности многозадачной системы. Один процесс не должен иметь возможности вмешаться в работу другого или получить доступ к его данным, ни по случайной ошибке, ни намеренно.
Во-вторых, проектирование и отладка программ чрезвычайно усложнились бы, если бы программист должен был учитывать непредсказуемое влияние других процессов.
С другой стороны, есть ситуации, когда взаимодействие необходимо. Процессы могут совместно обрабатывать общие данные, обмениваться сообщениями, ждать ответа и т.п. Система должна предоставлять в распоряжение процессов средства взаимодействия. Это не противоречит тому, что выше было сказано об изоляции процессов. Чтобы взаимодействие не привело к полному хаосу, оно должно выполняться только с помощью тех хорошо продуманных средств, которые предоставляет процессам ОС. За пределами этих средств действует изоляция процессов.
Понятие взаимодействия процессов включает в себя несколько видов взаимодействия, основными из которых являются:
· синхронизация процессов, т.е., упрощенно говоря, ожидание одним процессом каких-либо событий, связанных с работой других процессов
· обмен данными между процессами.
Серьезная проблема возникает в ситуации, когда два или более процесса
одновременно пытаются работать с общими для них данными, причем хотя бы один
процесс изменяет значение этих данных.
Совершенно иным образом подошел к проблеме взаимного исключения великий
голландский ученый Э.Дейкстра E.Dijkstra, 1966. Он предложил использовать новый
вид программных объектов — семафоры. Здесь мы рассмотрим их простейший вариант
— двоичные семафоры, они же мьютексы mutex, от слов MUTual EXclusion — взаимное
исключение.
Двоичным семафором называется переменная S, которая может принимать значения
0 и 1 и для которой определены только две операции.
PS — операция занятия закрытия семафора. Она ожидает, пока значение S не станет
равным 1, и, как только это случится, присваивает S значение 0 и завершает свое
выполнение. Очень важно: операция P по определению неделима, т.е. между
проверкой и присваиванием не может вклиниться другой процесс, который бы
изменил значение S.
VS — операция освобождения открытия семафора. Она просто присваивает S значение
0.
Чем переменная-семафор отличается от обычной булевой переменной Тем, что для нее недопустимы никакие иные операции, кроме P и V. Нельзя написать в программе S:=1 или ifSthen … , если S определена как семафор.
Заслуга Дейкстры как раз в том, что он разделил проблему взаимного исключения
на две независимые проблемы разных уровней:
на уровне реализации: как обеспечить работу семафоров в соответствии с их
определением
на уровне взаимодействия процессов: как написать корректно работающую программу, если в распоряжении программиста имеются семафоры.
Можно доказать, что использование двоичных семафоров позволяет корректно решить любые проблемы синхронизации процессов. Но вовсе не обязательно это решение окажется простым и удобным. В некоторых случаях использование семафоров должно все же сопровождаться нежелательным активным ожиданием.
За десятилетия, прошедшие после изобретения семафоров, были предложены различные средства синхронизации, более приспособленные для различных типовых задач. Рассмотрим некоторые из них.
Целочисленные семафоры. В упомянутой работе Дейкстры, помимо двоичных семафоров, принимающих значения 0 и 1, был рассмотрен также более общий тип семафоров со значениями на интервале от 0 до некоторого N. Функция PS уменьшает положительное значение семафора на 1, а при нулевом значении переходит в ожидание, как и в случае двоичного семафора. Функция VS увеличивает значение семафора на 1, но не более N.
Область применения целочисленных семафоров несколько иная, чем у двоичных. Целочисленные семафоры применяются в задачах выделения ресурсов из ограниченного запаса. Величина N характеризует общее количество имеющихся единиц ресурса, а текущее значение переменной — количество свободных единиц. При запросе ресурса процесс вызывает функцию VS, при освобождении — PS.
Для целочисленных семафоров иногда удобно использовать модифицированную функцию VS, k, вторым параметром которой является число одновременно запрашиваемых единиц ресурса. Такая функция блокирует процесс, если значение семафора меньше k.
Семафоры с множественным ожиданием. Возможна ситуация, когда процесс может выбрать один из нескольких путей дальнейшей работы, но на каждом пути он может быть заблокирован закрытым семафором. Разумно было бы ждать освобождения любого из семафоров и только тогда выбрать свободный путь. Но как это сделать Вызвав PS для одного из семафоров, процесс обречен ждать освобождения именно этого семафора, а не любого из имеющихся.
Житейская ситуация: покупатель в супермаркете, выбирающий, к какой из касс занять очередь. Хорошо бы угадать очередь, которая пройдет быстрее…
Функция множественного ожидания PS1, S2, … Sn позволяет указать в качестве параметров несколько двоичных семафоров или массив семафоров. Если хотя бы один из семафоров свободен, функция занимает его, в противном случае она ждет освобождения любого из семафоров.
Другой, не менее полезный вариант множественного ожидания, это ожидание момента, когда все указанные семафоры окажутся свободны. Это означает, что процесс может работать дальше только в том случае, если одновременно выполнены несколько условий, каждое из которых задано в виде двоичного семафора.
Сигнал — это нечто, что может быть послано процессу системой или другим
процессом. С сигналом не связано никакой информации, кроме номера кода,
указывающего, какой именно тип сигнала посылается. При получении сигнала
процесс прерывает свою текущую работу и переходит на выполнение функции,
определенной как обработчик сигналов данного типа.
Таким образом, сигналы сильно похожи на прерывания, но только высокоуровневые,
управляемые системой, а не аппаратурой.
Механизм сигналов позволяет решить, например, проблему критической секции иным способом, чем семафоры.
Сообщения также посылаются процессу системой или другим процессом, однако отличаются от сигналов в двух отношениях.
Во-первых, сообщения не прерывают работу процесса-получателя. Вместо этого они становятся в очередь сообщений. Процесс должен сам вызвать функцию приема сообщения. Если очередь пуста, эта функция блокирует процесс до получения какого-нибудь сообщения.
Во-вторых, с сообщением, в отличие от сигнала, может быть связана информация, передаваемая получателю. Таким образом, сообщения — это средство не только синхронизации, но и обмена данными между процессами.
Поговорим теперь еще об обмене данными. Самым простым и естественным способом такого обмена представляется возможность совместного доступа двух или более процессов к общей области памяти. Но поскольку обычно ОС стремится, наоборот, надежно разделить память разных процессов, то для выделения обшей памяти нужны специальные системные средства.
Общая память служит только средством обмена данными, но никак не решает проблем синхронизации. Участки программы, где происходит работа с общей памятью, часто следует рассматривать как критические секции и защищать семафорами.
Другое часто используемое средство обмена данными — программный канал pipe; иногда переводится как трубопровод. В этом случае для выполнения обмена используются не команды чтения записи в память, а функции чтения записи в файл. Программный канал притворяется файлом, для работы с ним используются те же операции, что для последовательного доступа к файлу: открытие, чтение, запись, закрытие. Однако источником читаемых данных служит не файл на диске, а процесс, выполняющий запись в другой конец трубы. Данные, записанные одним процессом, но пока не прочитанные другим, хранятся в системном буфере. Если же процесс пытается прочесть данные, которые пока не записаны другим процессом, то процесс-читатель блокируется до получения данных.
2.10. Способы реализации мультипрограммирования.
Мультипрограммирование — это способ организации вычислительного процесса, при котором на одном процессоре попеременно выполняются несколько программ. Пока одна программа выполняет операцию ввода-вывода, процессор не простаивает, как это происходило при последовательном выполнении программ однопрограммный режим, а выполняет другую программу многопрограммный режим.
Многозадачность почти синоним мультпрограммирования — способность ОС, обеспечивающая одновременное но не параллельное выполнение нескольких задач на одном процессоре. Существует несколько типов многозадачности. Самым простым является контекстное переключение, при котором загружаются два или более приложений, но процессорное время предоставляется только основному приложению foreground. Для выполнения фонового приложения background пользователь должен его активизировать. При кооперативной многозадачности фоновые задачи выполняются только во время простоя основного процесса например, ожидания события и только в том случае, если на это получено разрешение последнего.
В режиме разделения времени вытесняющая многозадачность процессорное время разделяется между задачами в соответствии с той или иной схемой приоритета.
Мультипрограммирование было реализовано в двух вариантах — в системах пакетной обработки и разделения времени.
Мультипрограммные системы пакетной обработки так же, как и их
однопрограммные предшественники, имели своей целью обеспечение максимальной загрузки аппаратуры компьютера, однако решали эту задачу более эффективно. В мультипрограммном пакетном режиме процессор не простаивал, пока одна программа выполняла операцию ввода-вывода как это происходило при последовательном выполнении программ в системах ранней пакетной обработки, а переключался на другую готовую к выполнению программу. В результате достигалась сбалансированная загрузка всех устройств компьютера, а следовательно, увеличивалось число задач, решаемых в единицу времени.
В мультипрограммных системах пакетной обработки пользователь по-прежнему был лишен возможности интерактивно взаимодействовать со своими программами. Для того чтобы хотя бы частично вернуть пользователям ощущение непосредственного взаимодействия с компьютером, был разработан другой вариант мультипрограммных систем — системы разделения времени. Этот вариант рассчитан на многотерминальные системы, когда каждый пользователь работает за своим терминалом. В числе первых операционных систем разделения времени, разработанных в середине 60-х годов, были TSS360 компания IBM, CTSS и MULTICS Массачусетский технологический институт совместно с Bell Labs и компанией General Electric.
Вариант мультипрограммирования, применяемый в системах разделения времени, был нацелен на создание для каждого отдельного пользователя иллюзии единоличного владения вычислительной машиной за счет периодического выделения каждой программе своей доли процессорного времени. В системах разделения времени эффективность использования оборудования ниже, чем в системах пакетной обработки, что явилось платой за удобства работы пользователя.
3.
Управление памятью
3.1. Организация памяти. Адресное пространство.
Необходимо отметить, что все распространенные операционные системы, если для работы нужно больше памяти, чем физически присутствует в компьютере, не прекращают работу, а сбрасывают неиспользуемое в данный момент содержимое памяти в дисковый файл называемый свопом — swap и затем по мере необходимости перегоняют данные между ОП и свопом. Это гораздо медленнее, чем доступ системы к самой ОП. Поэтому от количества оперативной памяти напрямую зависит скорость системы.
Команды, исполняемые ЭВМ при выполнении программы, равно как и числовые и
символьные операнды, хранятся в памяти компьютера. Память состоит из миллионов
ячеек, в каждой из которых содержится один бит информации значения 0 или 1.
Биты редко обрабатываются поодиночке, а, как правило, группами фиксированного
размера. Для этого память организуется таким образом, что группы по n бит могут
записываться и считывается за одну операцию. Группа n бит называется словом, а
значение n — длиной слова. Схематически память компьютера можно представить в
виде массива слов.
Обычно длина машинного слова компьютеров составляет от 16 до 64 бит. Если длина
слова равна 32 битам, в одном слове может храниться 32-разрядное число в
дополнительном коде или четыре символа ASCII, занимающих 8 бит каждый. Восемь
идущих подряд битов являются байтом. Для представления машинной команды
требуется одно или несколько слов.
Для доступа к памяти необходимы имена или адреса, определяющие расположение данных в памяти. В качестве адресов традиционно используются числа из диапазона от 0 до 2k- 1 со значением к, достаточным для адресации всей памяти компьютера. Все 2k адресов составляют адресное пространство компьютера. Следовательно, память состоит из 2kадресуемых элементов. Например, использование 24-разрядных как в процессоре 80286 адресов позволяет адресовать 224 16 777 216 элементов памяти. Обычно это количество адресуемых элементов обозначается как 16 Мбайт 1 Мбайт = 220 = 1 048 576 байт, адресное пространство 8086 и 80186. Поскольку у процессоров 80386.80486 Pentium и их аналогов 32-разрядные адреса, им соответствует адресное пространство в 232 байт, или 4 Гбайт.
Адресное пространство ЭВМ графически может быть изображено прямоугольником,
одна из сторон которого представляет разрядность адресуемой ячейки слова
процессора, а другая сторона — весь диапазон доступных адресов для этого же
процессора. Диапазон доступных адресов процессора определяется разрядностью
шины адреса системной шины. При этом минимальный номер ячейки памяти адрес
будет равен 0, а максимальный определяется из формулы M = 2n — 1.
Для шестнадцатиразрядной шины это будет 65 535 64 К.
Компромиссом между производительностью и объемами памяти является решение
использовать иерархию запоминающих устройств, то есть применять иерархическую модель
памяти.
Применение иерархических систем памяти оправдывает себя вследствие двух
важных факторов — принципа локальности обращений и низкого экономически
выгодного соотношения стоимостьпроизводительность. Принцип локальности
обращений состоит в том, что большинство программ обычно не выполняют обращений
ко всем своим командам и данным равновероятно, а в каждый момент времени
оказывают предпочтение некоторой части своего адресного пространства.
Иерархия памяти обычно состоит из многих уровней, но в каждый момент времени
взаимодействуют только два близлежащих уровня. Минимальная единица информации,
которая может присутствовать либо отсутствовать в двухуровневой иерархии,
называется блоком или строкой.
Успешное или не успешное обращение к более высокому уровню называют соответственно попаданием hit или промахом miss. Попадание — есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне.
Доля попаданий hit rаtе — доля обращений к данным, найденным на более высоком уровне. Доля промахов miss rate — это доля обращений к данным, которые не найдены на более высоком уровне.
Время обращения при попадании hit time есть время обращения к более высокому уровню иерархии, которое включает в себя, в частности, и время, необходимое для определения того, является ли обращение попаданием или промахом.
Потери на промах miss реnаltу есть время для замещения блока в более высоком уровне на блок из более низкого уровня плюс время для пересылки этого блока в требуемое устройство обычно в процессор.
Потери на промах далее включают в себя два компонента:
время доступа access time — время обращения к первому слову блока при промахе
время пересылки transfer time — дополнительное время для пересылки оставшихся слов блока. Время доступа связано с задержкой памяти более низкого уровня, а время пересылки — с полосой пропускания канала между устройствами памяти двух смежных уровней.
3.2. Методы управления памятью
При построении систем с иерархической памятью целью является получение
максимальной производительности подсистемы памяти при ее минимальной стоимости.
Эффективность той или иной системы кэш-памяти зависит от стратегии управления
памятью. Стратегия управления памятью включает: метод отображения основной памяти
в кэше; алгоритм взаимодействия между медленной основной и быстрой кэш-памятью;
стратегии замещения информации в кэше.
Существует три основных способа размещения блоков строк основной памяти в кэше:
кэш-память с прямым отображением direct-mapped cache
полностью ассоциативная кэш-память fully associative cache.
частично ассоциативная или множественно ассоциативная, partial associative,
set-associative cache кэш-память
Память с прямым отображением. В этом случае каждый блок основной памяти
имеет только одно фиксированное место, на котором он может появиться в
кэш-памяти. Все блоки основной памяти, имеющие одинаковые младшие разряды в
своем адресе, попадают в один блок кэш-памяти. При таком подходе справедливо
соотношение:
Адрес блока кэш-памяти = Адрес блока основной памяти mod Число блоков в
кэш-памяти.
Этот тип памяти наиболее прост, но и наименее эффективен, так как данные из разных областей памяти могут конфликтовать из-за единственной строки кэша, где они только и могут быть размещены.
Полностью ассоциативная память
Может отображать содержимое любой области памяти в любую область кэша, но при этом крайне сложна в схемотехнике.
Частично-ассоциативный кэш
Является наиболее распространенным в данный момент среди процессорных
архитектур. Характеризуется тем или иным количеством n каналов степенью
ассоциативности, п-way и может отображать содержимое данной строки памяти на
каждую из n своих строк. Этот вариант является разумным компромиссом между
полностью ассоциативным и кэшем прямого отображения.
В современных процессорах, как правило, используется либо кэш-память с прямым
отображением, либо двух- четырех- канальная множественно ассоциативная
кэш-память. Например, в архитектурах К7 и К8 применяется 16-канальный
частично-ассоциативный кэш L2.
Стратегия замещения информации в кэше определяет блок, подлежащий замещению при возникновении промаха. Простота при использовании кэша с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые: легко реализуется сама аппаратура, легко происходит замещение данных. При замещении просто нечего выбирать — на попадание проверяется только один блок и только этот блок может быть замещен.
При полностью или частично ассоциативной организации кэш-памяти имеются
несколько блоков, из которых надо выбрать кандидата в случае промаха. Как
правило, для замещения блоков применяются две основные стратегии:
случайная Random — блоки-кандидаты выбираются случайно равномерное
распределение. В некоторых системах используют псевдослучайный алгоритм
замещения
замещается тот блок, который не использовался дольше всех LRU — Least-Recently Used. В этом случае чтобы уменьшить вероятность удаления информации, которая скоро может потребоваться, все обращения к блокам фиксируются.
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным.
Алгоритмы обмена с кэш-памятью свопинга включают следующие разновидности:
· алгоритм сквозной записи Write Through или сквозного накопления Store Through
· алгоритм простого свопинга Simple Swapping или обратной записи Write Back
· алгоритм свопинга с флагами Flag Swapping или обратной записи в конфликтных ситуациях с флагами CUX
· алгоритм регистрового свопинга с флагами FRS.
Алгоритм сквозной записи
Самый простой алгоритм свопинга. Каждый раз при появлении запроса на запись по некоторому адресу обновляется содержимое области по этому адресу как в быстрой, так и в основной памяти, даже если копия содержимого по этому адресу находится в быстром буфере. Такое постоянное обновление содержимого основной памяти, как и буфера, при каждом запросе на запись позволяет постоянно поддерживать информацию, находящуюся в основной памяти, в обновленном состоянии.
Поэтому, когда возникает запрос на запись по адресу, относящемуся к области,
содержимое которой не находится в данный момент в быстром буфере, новая
информация записывается просто на место блока, которое предполагается переслать
в основную память без необходимости пересылки этого слова в основную память,
так как в основной памяти уже находится его достоверная копия.
Алгоритм простого свопинга
Обращения к основной памяти имеют место в тех случаях, когда в быстром
буфере не обнаруживается нужное слово. Эта схема свопинга повышает
производительность системы памяти, так как в ней обращения к основной памяти не
происходят при каждом запросе на запись, что имеет место при использовании
алгоритма сквозной записи. Однако в связи с тем, что содержимое основной памяти
не поддерживается в постоянно обновленном состоянии, если необходимого слова в
быстром буфере не обнаруживается, из буфера в основную память надо возвратить
какое-либо устаревшее слово, чтобы освободить место для нового необходимого
слова. Поэтому из буфера в основную память сначала пересылается какое-то слово,
место которого занимает в буфере нужное слово. Таким образом, происходят две
пересылки между быстрым буфером и основной памятью.
Алгоритм свопинга с флагами
Данный алгоритм является улучшением алгоритма простого свопинга. В алгоритме
простого свопинга, когда в кэш-памяти не обнаруживается нужное слово,
происходит два обращения к основной памяти — запись удаляемого значения из кэша
и чтение нового значения в кэш. Если слово с того момента, как оно попало в
буфер из основной памяти, не подвергалось изменениям, то есть по его адресу не
производилась запись оно использовалось только для чтения, то нет необходимости
пересылать его обратно в основную память, потому что в ней и так имеется
достоверная его копия; это обстоятельство позволяет в ряде случаев обойтись без
обращений к основной памяти. Если, однако, слово подвергалось изменениям с тех
пор, когда его копия была в последний раз записана обратно в основную память,
то приходится перемещать его в основную память. Отслеживать изменения слова
можно, пометив слово блок дополнительным флаг-битом. Изменяя значение флаг-бита
при изменении слова, можно сформировать информацию о состоянии слова.
Пересылать в основную память необходимо лишь те слова, флаги которых
оказываются в установленном состоянии.
Алгоритм регистрового свопинга с флагами
Повышение эффективности алгоритма свопинга с флагами возможно за счет уменьшения эффективного времени цикла, что можно получить при введении регистра регистров временного хранения между кэш-памятью и основной памятью. Теперь, если данные должны быть переданы из быстрого буфера в основную память, они сначала пересылаются в регистр регистры временного хранения; новое слово сразу же пересылается в буфер из основной памяти, а уже потом слово, временно хранившееся в регистре, записывается в основную память. Действия в ЦП начинают опять выполняться, как только для этого возникает возможность. Алгоритм обеспечивает совмещение операций записи в основную память с обычными операциями над буфером, что обеспечивает еще большее повышение производительности.
Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш — когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти.
3.3. Принципы организации виртуальной памяти
Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем.
В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение.
Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти на диске и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней дисковой памятью.
Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти.
Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами. Ниже рассмотрены оба типа организации виртуальной памяти.
3.4. Сегментная организация памяти
Сегментный подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля.
Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных сегменты стека являются частным случаем сегментов данных. Поскольку общие программы должны обладать свойством повторной входимости, то из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной и любой сегмент данных может быть защищен от обращений по записи или по чтению.
Для реализации сегментации было предложено несколько схем, которые отличаются деталями реализации, но основаны на одних и тех же принципах.
В системах с сегментацией памяти каждое слово в адресном пространстве пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер сегмента, а младшие — как номер слова внутри сегмента. Наряду с сегментацией может также использоваться страничная организация памяти. В этом случае виртуальный адрес слова состоит из трех частей: старшие разряды адреса определяют номер сегмента, средние — номер страницы внутри сегмента, а младшие — номер слова внутри страницы.
Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель дескриптор сегмента поля базы, границы и индикаторов режима доступа. При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница — длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница — число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения.
Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов базу и границу, причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница — длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память.
Отметим, что в описанной схеме сегментации таблица сегментов с индикаторами доступа предоставляет всем программам, являющимся частями некоторой задачи, одинаковые возможности доступа, т. е. она определяет единственную область домен защиты. Однако для создания защищенных подсистем в рамках одной задачи для того, чтобы изменять возможности доступа, когда точка выполнения переходит через различные программы, управляющие ее решением, необходимо связать с каждой задачей множество доменов защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств. Рассмотрение таких систем, которые включают в себя кольцевые схемы защиты, а также различного рода мандатные схемы защиты, выходит за рамки данного обзора.
3.5. Страничная организация памяти
В системах со страничной организацией основная и внешняя память главным образом дисковое пространство делятся на блоки или страницы фиксированной длины. Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие — как номер слова или байта внутри страницы.
Управление различными уровнями памяти осуществляется программами ядра
операционной системы, которые следят за распределением страниц и оптимизируют
обмены между этими уровнями. При страничной организации памяти смежные
виртуальные страницы не обязательно должны размещаться на смежных страницах
основной физической памяти. Для указания соответствия между виртуальными
страницами и страницами основной памяти операционная система должна
сформировать таблицу страниц для каждой программы и разместить ее в основной
памяти машины. При этом каждой странице программы, независимо от того находится
ли она в основной памяти или нет, ставится в соответствие некоторый элемент
таблицы страниц. Каждый элемент таблицы страниц содержит номер физической
страницы основной памяти и специальный индикатор. Единичное состояние этого
индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое
состояние индикатора означает отсутствие страницы в оперативной памяти.
Для увеличения эффективности такого типа схем в процессорах используется
специальная полностью ассоциативная кэш-память, которая также называется
буфером преобразования адресов TLB traнсlation-lookaside buffer. Хотя наличие
TLB не меняет принципа построения схемы страничной организации, с точки зрения
защиты памяти, необходимо предусмотреть возможность очистки его при
переключении с одной программы на другую.
Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель дескриптор таблицы страниц или базово-граничную пару. База определяет адрес начала таблицы страниц в основной памяти, а граница — длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы.
Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц.
Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц. Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти. Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами.
3.6. Ускорение работы страничной памяти
Другой подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля.
Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных сегменты стека являются частным случаем сегментов данных. Поскольку общие программы должны обладать свойством повторной входимости, то из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной и любой сегмент данных может быть защищен от обращений по записи или по чтению.
Для реализации сегментации было предложено несколько схем, которые отличаются
деталями реализации, но основаны на одних и тех же принципах.
В системах с сегментацией памяти каждое слово в адресном пространстве
пользователя определяется виртуальным адресом, состоящим из двух частей:
старшие разряды адреса рассматриваются как номер сегмента, а младшие — как
номер слова внутри сегмента. Наряду с сегментацией может также использоваться
страничная организация памяти. В этом случае виртуальный адрес слова состоит из
трех частей: старшие разряды адреса определяют номер сегмента, средние — номер
страницы внутри сегмента, а младшие — номер слова внутри страницы.
Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель дескриптор сегмента поля базы, границы и индикаторов режима доступа. При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница — длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница — число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения.
Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов базу и границу, причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница — длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память.
Отметим, что в описанной схеме сегментации таблица сегментов с индикаторами доступа предоставляет всем программам, являющимся частями некоторой задачи, одинаковые возможности доступа, т. е. она определяет единственную область домен защиты. Однако для создания защищенных подсистем в рамках одной задачи для того, чтобы изменять возможности доступа, когда точка выполнения переходит через различные программы, управляющие ее решением, необходимо связать с каждой задачей множество доменов защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств. Рассмотрение таких систем, которые включают в себя кольцевые схемы защиты, а также различного рода мандатные схемы защиты, выходит за рамки данного обзора.
3.7. Принципы замещения страниц
Итак, наиболее ответственным действием менеджера памяти является выделение кадра оперативной памяти для размещения в ней виртуальной страницы, находящейся во внешней памяти. Напомним, что мы рассматриваем ситуацию, когда размер виртуальной памяти для каждого процесса может существенно превосходить размер основной памяти. Это означает, что при выделении страницы основной памяти с большой вероятностью не удастся найти свободный страничный кадр. В этом случае операционная система в соответствии с заложенными в нее критериями должна:
· найти некоторую занятую страницу основной памяти
· переместить в случае надобности ее содержимое во внешнюю память
· переписать в этот страничный кадр содержимое нужной виртуальной страницы из внешней памяти
· должным образом модифицировать необходимый элемент соответствующей таблицы страниц
· продолжить выполнение процесса, которому эта виртуальная страница понадобилась.
Заметим, что при замещении приходится дважды передавать страницу между основной и вторичной памятью. Процесс замещения может быть оптимизирован за счет использования бита модификации один из атрибутов страницы в таблице страниц. Бит модификации устанавливается компьютером, если хотя бы один байт был записан на страницу. При выборе кандидата на замещение проверяется бит модификации. Если бит не установлен, нет необходимости переписывать данную страницу на диск, ее копия на диске уже имеется. Подобный метод также применяется к read-only-страницам, они никогда не модифицируются. Эта схема уменьшает время обработки page fault.
Существует большое количество разнообразных алгоритмов замещения страниц. Все они делятся на локальные и глобальные. Локальные алгоритмы, в отличие от глобальных, распределяют фиксированное или динамически настраиваемое число страниц для каждого процесса. Когда процесс израсходует все предназначенные ему страницы, система будет удалять из физической памяти одну из его страниц, а не из страниц других процессов. Глобальный же алгоритм замещения в случае возникновения исключительной ситуации удовлетворится освобождением любой физической страницы, независимо от того, какому процессу она принадлежала.
Глобальные алгоритмы имеют ряд недостатков. Во-первых, они делают одни процессы чувствительными к поведению других процессов. Например, если один процесс в системе одновременно использует большое количество страниц памяти, то все остальные приложения будут в результате ощущать сильное замедление из-за недостатка кадров памяти для своей работы. Во-вторых, некорректно работающее приложение может подорвать работу всей системы если, конечно, в системе не предусмотрено ограничение на размер памяти, выделяемой процессу, пытаясь захватить больше памяти. Поэтому в многозадачной системе иногда приходится использовать более сложные локальные алгоритмы. Применение локальных алгоритмов требует хранения в операционной системе списка физических кадров, выделенных каждому процессу. Этот список страниц иногда называют резидентным множеством процесса. В одном из следующих разделов рассмотрен вариант алгоритма подкачки, основанный на приведении резидентного множества в соответствие так называемому рабочему набору процесса.
Эффективность алгоритма обычно оценивается на конкретной последовательности ссылок к памяти, для которой подсчитывается число возникающих page faults. Эта последовательность называется строкой обращений reference string. Мы можем генерировать строку обращений искусственным образом при помощи датчика случайных чисел или трассируя конкретную систему. Последний метод дает слишком много ссылок, для уменьшения числа которых можно сделать две вещи:
· для конкретного размера страниц можно запоминать только их номера, а не адреса, на которые идет ссылка
· несколько подряд идущих ссылок на одну страницу можно фиксировать один раз.
Как уже говорилось, большинство процессоров имеют простейшие аппаратные средства, позволяющие собирать некоторую статистику обращений к памяти. Эти средства обычно включают два специальных флага на каждый элемент таблицы страниц. Флаг ссылки reference бит автоматически устанавливается, когда происходит любое обращение к этой странице, а уже рассмотренный выше флаг изменения modify бит устанавливается, если производится запись в эту страницу. Операционная система периодически проверяет установку таких флагов, для того чтобы выделить активно используемые страницы, после чего значения этих флагов сбрасываются.
3.8. Алгоритмы замещения страниц
Алгоритм FIFO. Выталкивание первой пришедшей страницы
Простейший алгоритм. Каждой странице присваивается временная метка. Реализуется
это просто созданием очереди страниц, в конец которой страницы попадают, когда
загружаются в физическую память, а из начала берутся, когда требуется
освободить память. Для замещения выбирается старейшая страница. К сожалению,
эта стратегия с достаточной вероятностью будет приводить к замещению активно
используемых страниц, например страниц кода текстового процессора при
редактировании файла. Заметим, что при замещении активных страниц все работает
корректно, но page fault происходит немедленно.
Аномалия Билэди Belady
На первый взгляд кажется очевидным, что чем больше в памяти страничных кадров,
тем реже будут иметь место page faults. Удивительно, но это не всегда так.Как
установил Билэди с коллегами, определенные последовательности обращений к
страницам в действительности приводят к увеличению числа страничных нарушений
при увеличении кадров, выделенных процессу. Это явление носит название аномалии
Билэди или аномалии FIFO .
Система с тремя кадрами 9 faults оказывается более производительной, чем с
четырьмя кадрами 10 faults, для строки обращений к памяти 012301401234 при
выборе стратегии FIFO.

Рис. 10.1. Аномалия Билэди: a — FIFO с тремя страничными кадрами; b — FIFO с
четырьмя страничными кадрами
Аномалию Билэди следует считать скорее курьезом, чем фактором, требующим
серьезного отношения, который иллюстрирует сложность ОС, где интуитивный подход
не всегда приемлем.
Оптимальный алгоритм OPT
Одним из последствий открытия аномалии
Билэди стал поиск оптимального алгоритма, который при заданной строке обращений
имел бы минимальную частоту page faults среди всех других алгоритмов. Такой
алгоритм был найден. Он прост: замещай страницу, которая не будет
использоваться в течение самого длительного периода времени.
Каждая страница должна быть помечена числом инструкций, которые будут
выполнены, прежде чем на эту страницу будет сделана первая ссылка.
Выталкиваться должна страница, для которой это число наибольшее.
Этот алгоритм легко описать, но реализовать невозможно. ОС не знает, к какой странице
будет следующее обращение. Ранее такие проблемы возникали при планировании
процессов — алгоритм SJF.
Зато мы можем сделать вывод, что для того, чтобы алгоритм замещения был
максимально близок к идеальному алгоритму, система должна как можно точнее предсказывать
обращения процессов к памяти. Данный алгоритм применяется для оценки качества
реализуемых алгоритмов.
Выталкивание дольше всего не использовавшейся страницы. Алгоритм LRU
Одним из приближений к алгоритму OPT является алгоритм, исходящий из эвристического
правила, что недавнее прошлое — хороший ориентир для прогнозирования ближайшего
будущего.
Ключевое отличие между FIFO и оптимальным алгоритмом заключается в том, что
один смотрит назад, а другой вперед. Если использовать прошлое для аппроксимации
будущего, имеет смысл замещать страницу, которая не использовалась в течение
самого долгого времени. Такой подход называется least recently used алгоритм
LRU . Работа алгоритма проиллюстрирована на рис. рис. 10.2. Сравнивая рис. 10.1
b и 10.2, можно увидеть, что использование LRU алгоритма позволяет сократить
количество страничных нарушений.

Рис. 10.2. Пример работы алгоритма LRU
LRU — хороший, но труднореализуемый алгоритм. Необходимо иметь связанный список
всех страниц в памяти, в начале которого будут хранится недавно использованные
страницы. Причем этот список должен обновляться при каждом обращении к памяти.
Много времени нужно и на поиск страниц в таком списке.
В [Таненбаум, 2002] рассмотрен вариант реализации алгоритма LRU со специальным
64-битным указателем, который автоматически увеличивается на единицу после
выполнения каждой инструкции, а в таблице страниц имеется соответствующее поле,
в которое заносится значение указателя при каждой ссылке на страницу. При
возникновении page fault выгружается страница с наименьшим значением этого
поля.
Как оптимальный алгоритм, так и LRU не страдают от аномалии Билэди. Существует
класс алгоритмов, для которых при одной и той же строке обращений множество
страниц в памяти для n кадров всегда является подмножеством страниц для n+1
кадра. Эти алгоритмы не проявляют аномалии Билэди и называются стековыми stack
алгоритмами.
Выталкивание редко используемой страницы. Алгоритм NFU
Поскольку большинство современных процессоров не предоставляют соответствующей
аппаратной поддержки для реализации алгоритма LRU, хотелось бы иметь алгоритм,
достаточно близкий к LRU, но не требующий специальной поддержки.
Программная реализация алгоритма, близкого к LRU, — алгоритм NFUNot Frequently
Used.
Для него требуются программные счетчики, по одному на каждую страницу, которые
сначала равны нулю. При каждом прерывании по времени а не после каждой инструкции
операционная система сканирует все страницы в памяти и у каждой страницы с
установленным флагом обращения увеличивает на единицу значение счетчика, а флаг
обращения сбрасывает.
Таким образом, кандидатом на освобождение оказывается страница с наименьшим
значением счетчика, как страница, к которой реже всего обращались. Главный
недостаток алгоритма NFU состоит в том, что он ничего не забывает. Например,
страница, к которой очень часто обращались в течение некоторого времени, а
потом обращаться перестали, все равно не будет удалена из памяти, потому что ее
счетчик содержит большую величину. Например, в многопроходных компиляторах
страницы, которые активно использовались во время первого прохода, могут
надолго сохранить большие значения счетчика, мешая загрузке полезных в
дальнейшем страниц.
К счастью, возможна небольшая модификация алгоритма, которая позволяет ему
забывать. Достаточно, чтобы при каждом прерывании по времени содержимое
счетчика сдвигалось вправо на 1 бит, а уже затем производилось бы его увеличение
для страниц с установленным флагом обращения.
Другим, уже более устойчивым недостатком алгоритма является длительность
процесса сканирования таблиц страниц.
4.
Управление вводом-выводом
4.1. Прерывания от внешних устройств
Смотри пункт 1.3
4.2. Классификация устройств ввода-вывода
Классификация по способу вывода
По способу ввода-вывода информации на периферийное устройство используют
следующую классификацию:
1. Прямое программирование устройств. При этом способе программа сама, без
помощи других программ, программирует периферийное устройство. Хотя этот способ
является исторически первым и обеспечивает максимальное быстродействие, в
настоящее время он не используется из-за своей практической непереносимости
между компьютерами.
2. Прямое программирование через драйвер устройства. Драйвер — это такая
программа, которая перехватывает обращение пользователя или операционной
системы к периферийному устройству, предлагая более или менее унифицированный
интерфейс функций для работы с устройством. При этом пользователю не нужно
вникать в аппаратную реализацию устройства, обращаться к регистрам и портам
устройства по уникальным адресам, и, в конце концов, держать всю эту информацию
в своей голове. Драйвер предоставляет доступ к функциям управления устройствами
либо через прерывания в MS-DOS, либо через специальные функции операционной
системы Windows, Unix, либо как некоторый объект с методами Win32 и др..
Недостаток этого метода заключается в том, что написать один драйвер с
интерфейсом на все случаи жизни не представляется возможным. Поэтому
программирование через драйвер устройства является также сложной работой даже
для профессионалов, однако такого рода ввод-вывод является: вводом-выводом
среднего уровня. На практике используется ввод-вывод высокого уровня, когда с
драйвером устройства будет работать одна или несколько промежуточных программ,
обеспечивающих единый интерфейс ввода-вывода для прикладных программ.
3. Буферизированный потоковый ввод-вывод. Этот вывод реализован на уровне
консоли в MS-DOS, Windows и UNIX. При этом способе в оперативной памяти ЭВМ
создаётся буфер для записи или считывания из него символов, и непосредственным
их вводом-выводом на устройство занимается операционная система.
Недостатки буферизированного ввода-вывода следующие:
· при таком вводе-выводе невозможно задать шрифтовое и абзацное оформление текста — используется только поток символов
· такой ввод-вывод ограничен консолью и консольными операциями перенаправления вывода. С его помощью нельзя реализовать WIMP, SILK и другие интерфейсы
· редактировать такой поток можно только с помощью внешних программ-редакторов.
Преимуществом же потокового способа ввода-вывода является возможность гибко перенаправлять потоки с устройства на устройство из числа тех, которые поддерживает операционная система.
4. Ввод-вывод с использованием API. Термин API расшифровывается как Application Programming Interface — интерфейс программирования приложений. С помощью этого интерфейса можно создавать программы на высоком уровне абстракции от реальной конфигурации ЭВМ и периферийных устройств. Программа описывает свои действия на языке в общем виде, все детали формирования изображения и ввода-вывода от него скрыты. Программист может задавать шрифтовое и абзацное оформление, выводить графику вместе с текстом — всё это будет реализовано одинаково на любом устройстве, которое поддерживает данное API. Недостатки такого вывода следующие:
· больший, по сравнению с буферизированным вводом-выводом, размер кода и количество подготовительных операций перед выводом
· привязка ввода-вывода к одному API, а значит — к определённой платформе ЭВМ, библиотекам и операционным системам
· невозможность оперативного, без помощи программиста, перенаправления вывода.
Этими способами реализации ввода-вывода в основном ограничиваются операции ввода-вывода в разных языках программирования и операционных системах.
Классификация по обработке
По способу обработки информации при её вводе-выводе различают форматированный и неформатированный бинарный ввод-вывод.
При форматированном вводе проводятся следующие операции:
1. Задаётся ограничение на размер строки символов, читаемых с устройства
2. Числовые данные при вводе преобразуются в двоичные в соответствии с их форматом
3. При чтении чисел проверяется их формат, а именно:
длину строки цифр
наличие и местоположение десятичной точки
наличие и значение символа порядка при чтении чисел в научном формате
4. Целые числа, в зависимости от формата чтения, могут быть десятичными, восьмеричными, шестнадцатеричными, датой, временем и т.п. Всё это указывается в опциях формата, задаваемых в операциях ввода.
При форматированном выводе производятся операции, противоположные тем, что применялись при вводе, а именно:
1. Данные из двоичной формы преобразуются в текстовую форму, в соответствии со строкой формата
2. Эти текстовые данные обрезаются до определённой длины, а также осуществляется выравнивание текстовой информации в выводимой строке.
При неформатированном текстовом выводе данные переводятся в текстовый формат, однако при этом не задаётся ни ограничение на длину, ни на выравнивание символов, ни на положение десятичной точки. Читать такие данные неудобно, а тем более — передавать их обратно машине.
Существует также неформатированный двоичный ввод-вывод, когда данные передаются на устройство или считываются с него как есть, безо всяких преобразований. Такие файлы являются, как правило, двоичными бинарными.
Кроме того, следует отметить, что записи данных, которые передаются устройству ввода-вывода за один приём, могут иметь фиксированную или переменную длину всё равно, являются они форматированными или нет. Тогда к файлу, запись которого имеет фиксированную длину, можно организовать прямой доступ, т.е. любую его запись можно прочитать, зная начало файла и номер смещение записи в файле. Это очень удобно при организации баз данных.
4.3. Основные принципы организации ввода — вывода
Каждое устройство ввода-вывода вычислительной системы — диск, принтер, терминал и т. п. — снабжено специализированным блоком управления, называемым контроллером. Контроллер взаимодействует с драйвером — системным программным модулем, предназначенным для управления данным устройством. Контроллер периодически принимает от драйвера выводимую на устройство информацию, а также команды управления, которые говорят о том, что с этой информацией нужно сделать например, вывести в виде текста в определенную область терминала или записать в определенный сектор диска. Под управлением контроллера устройство может некоторое время выполнять свои операции автономно, не требуя внимания со стороны центрального процессора. Это время зависит от многих факторов — объема выводимой информации, степени интеллектуальности управляющего устройством контроллера, быстродействия устройства и т. п. Даже самый примитивный контроллер, выполняющий простые функции, обычно тратит довольно много времени на самостоятельную реализацию подобной функции после получения очередной команды от процессора. Это же справедливо и для сложных контроллеров, так как скорость работы любого устройства ввода-вывода, даже самого скоростного, обычно существенно ниже скорости работы процессора.
Процессы, происходящие в контроллерах, протекают в периоды между выдачами команд независимо от ОС. От подсистемы ввода-вывода требуется спланировать в реальном масштабе времени в котором работают внешние устройства запуск и приостановку большого количества разнообразных драйверов, обеспечив приемлемое время реакции каждого драйвера на независимые события контроллера. С другой стороны, необходимо минимизировать загрузку процессора задачами ввода-вывода, оставив как можно больше процессорного времени на выполнение пользовательских потоков.
Данная задача является классической задачей планирования систем реального времени и обычно решается на основе многоуровневой приоритетной схемы обслуживания по прерываниям. Для обеспечения приемлемого уровня реакции все драйверы или части драйверов распределяются по нескольким приоритетным уровням в соответствии с требованиями ко времени реакции и временем использования процессора. Для реализации приоритетной схемы обычно задействуется общий диспетчер прерываний ОС.
4.4. Функции супервизора ввода-вывода
Основные задачи супервизора:
1 супервизор задач модуль супервизора ОС получает запросы от прикладных задач
на выполнение тех или иных операций, в том числе на ввод-вывод. Эти запросы
проверяются на корректность и, если они соответствуют спецификациям и не
содержат ошибок, то обрабатываются дальше
2 супервизор ввода-вывода получает запросы на ввод-вывод от супервизора задач или от программных модулей самой операционной системы.
3 супервизор ввода-вывода вызывает соответствующие распределители каналов и
контроллеров, планирует ввод-вывод Запрос на ввод-вывод либо тут же
выполняется, либо ставится в очередь на выполнение.
4 супервизор ввода-вывода инициирует операции ввода-вывода и при использовании
прерываний предоставляет процессор диспетчеру задач, чтобы передать его первой
задаче, стоящей в очереди на выполнение
5 при получении сигналов прерываний от устройств ввода-вывода супервизор идентифицирует эти сигналы и передает управление соответствующим программам обработки прерываний
6 супервизор
ввода-вывода осуществляет передачу сообщений об ошибках, если таковые происходят в процессе управления операциями ввода-вывода.
7 супервизор ввода-вывода посылает сообщения о завершении операции ввода-вывода запросившей эту операцию задаче и снимает ее с состояния ожидания ввода-вывода, если задача ожидала завершения операции.
4.5. Режимы управления вводом-выводом
Существует 2 основных режима ввода-вывода
1. режим обмена опросом готовности устройства ввода-вывода
2. режим обмена с прерыванием
Для организации ввода-вывода по 1 варианту процессор посылает устройству
управления команду для устройства ввода-вывода выполнить некоторое действие.
Устройство управления выполнит команду преобразования, её сигналы управления,
которое оно передает устройству ввода-вывода. Поскольку быстродействие
устройства ввода-вывода меньше на несколько порядков устройства быстродействия
процессора, то драйвер управляющий обилием данных с внешних устройств вынужден
в цикле опрашивать готовность устройств. При этом нерационально используется
время процессора. Выгоднее после команды ввода-вывода перейти на выполнение
другой команды, а появление сигнала готовности трактовать как запрос на
прерывание. Драйверы работающие в режиме прерывания представляют собой сложный
комплекс программных модулей и имеют несколько секций:
· секция запуска
· секция продолжения
· секция завершения
Секция запуска запускается для включения устройств ввода-вывода либо для инициализации очередной операции ввода-вывода .
Секция продолжения осуществляет основную работу по передаче данных
Секция завершения выключает устройства ввода-вывода либо просто завершает операцию.
Управление операциями ввода-вывода в режиме прерывания требует более сложных программ чем те, что работают в режиме опроса готовности.
Так, в операционных системах Windows 95,98 и Windows NT драйвер печати через параллельный код работает не в режиме прерывания, а в режиме опроса готовности, что приводит к 100% загрузке процессора на все время печати. Для организации и выполнения многие параллельно выполняющиеся задачи устройств ввода-вывода вводится понятие виртуального устройства, повышающего эффективность вычислительных систем. Примером служит spooling, то есть имитация работы с устройством в режиме on-line. Главная задача spoolingа — создать единицу параллельно выполняемого устройства ввода-вывода с последовательным доступом.
4.6. Закрепление устройств, общие устройства ввода-вывода.
Как известно, многие устройства и, прежде всего, устройства с последовательным доступом не допускают совместного использования. Такие устройства могут стать закрепленными за процессом, то есть их можно предоставить некоторому вычислительному процессу на все время жизни этого процесса. Однако это приводит к тому, что вычислительные процессы часто не могут выполняться параллельно — они ожидают освобождения устройств ввода-вывода. Чтобы организовать совместное использование многими параллельно выполняющимися задачами тех устройств ввода-вывода, которые не могут быть разделяемыми, вводится понятие виртуальных устройств. Принцип виртуализации позволяет повысить эффективность вычислительной системы.
Вообще говоря, понятие виртуального устройства шире, нежели понятие спулинга spooling — Simultaneous Peripheral Operation On-Line, то есть имитация работы с устройством в режиме непосредственного подключения к нему. Основное назначение спулинга — создать видимость разделения устройства ввода-вывода, которое фактически является устройством с последовательным доступом и должно использоваться только монопольно и быть закрепленным за процессом. Например, мы уже говорили, что в случае, когда несколько приложений должны выводить на печать результаты своей работы, если разрешить каждому такому приложению печатать строку по первому же требованию, то это приведет к потоку строк не представляющих никакой ценности. Однако если каждому вычислительному процессу предоставлять не реальный, а виртуальный принтер, и поток выводимых символов или управляющих кодов для их печати сначала направлять в специальный файл на диске так называемый спул-файл — spool-file и только потом, по окончании виртуальной печати, в соответствии с принятой дисциплиной обслуживания и приоритетами приложений выводить содержимое спул-файла на принтер, то все результаты работы можно будет легко читать. Системные процессы, которые управляют спул-файлом, называются спулером чтения spool-reader или спулером записи spool-writer.
Достаточно рационально организована работа с виртуальными устройствами в
системах Windows 9xNT2000XP компании Microsoft. В качестве примера можно кратко
рассмотреть подсистему печати. Microsoft различает термины принтер и устройство
печати. Принтер — это некоторая виртуализация, объект операционной системы, а
устройство печати — это физическое устройство, которое может быть подключено к
компьютеру. Принтер может быть локальным или сетевым. При установке локального
принтера в операционной системе создается новый объект, связанный с реальным
устройством печати через тот или иной интерфейс. Интерфейс может быть и сетевым,
то есть передача управляющих кодов в устройство печати может осуществляться
через локальную вычислительную сеть, однако принтер все равно будет считаться
локальным.
Локальность принтера означает, что его спул-файл будет находиться на том же
компьютере, что и принтер. Если же некоторый локальный принтер предоставить в
сети в общий доступ с теми или иными разрешениями, то для других компьютеров и
их пользователей он может стать сетевым, Компьютер, на котором имеется
локальный принтер, предоставленный в общий доступ, называется принт-сервером.
4.7. Основные системные таблицы ввода-вывода
Организация ввода-вывода требует наличия информации о ресурсах устройствах и
их состоянии. Эта информация обычно хранится в системных таблицах, основными из
которых являются:
- таблица оборудования ET — eguipment table, список УВВ, подключенных к системе
- таблица виртуальных логических устройств DRT — device reference table
- таблица прерываний IT — interrupt table.
Отдельный элемент первой таблицы называется блоком управления
соответствующим устройством обмена UCB — unit control block и содержит
следующую информацию об устройстве:
- тип, модель, имя и характеристики устройства
- характеристики подключения тип интерфейса, порт, линия запроса прерывания
- указание на драйвер управления и адреса его секций
- наличие и адрес буфера обмена для устройства
- уставка тайм-аута и адрес ячейки хранения счетчика тайм-аута
- состояние устройства
- дескриптор задачи, использующий устройство в данный момент времени и т.п.
Вторая таблица DRT избавляет программиста от необходимости знания конкретных параметров устройства. Обращаясь к логическому имени устройства, программист посредством таблицы описания виртуальных логических устройств устанавливает связь с конкретным устройством. Т.о., эта таблица перенаправляет запрос ввода-вывода на те модули и структуры данных, которые хранятся в соответствующем элементе первой таблицы.
Третья таблица IT для каждого запроса на прерывание указывает UCB, сопоставленный этому запросу.
Взаимосвязи названных системных таблиц показаны на рис. 24.
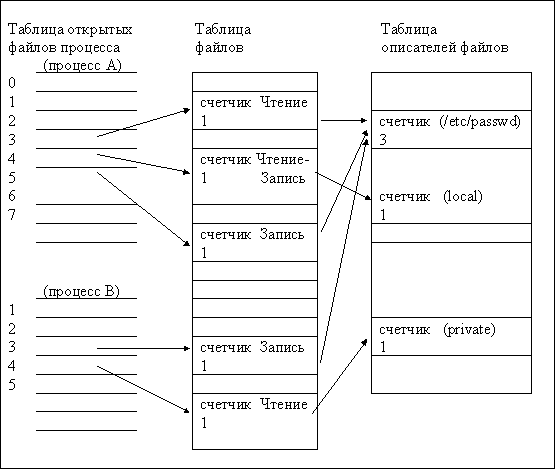
Рис. 24. Взаимосвязь системных таблиц ввода-вывода
Запрос на ввод-вывод от выполняющейся программы поступает на супервизор программ действие 1. Он проверяет вызов на соответствие принятым спецификациям. В случае корректности запроса он перенаправляется в супервизор ввода-вывода действие 2, иначе задаче возвращается соответствующее сообщение действие 1-1.
Супервизор ввода-вывода по логическому виртуальному имени таблицы DRT
находит соответствующий элемент UCB в таблице оборудования. Если устройство
занято, то описатель задачи помещается в очередь к устройству, иначе
запускается препроцессор ввода-вывода. Он формирует последовательность
управляемых кодов и данных для устройства ввода-вывода. Когда
последовательность сформирована, супервизор ввода-вывода передает управление
соответствующему драйверу в секции запуска действие 3.
Драйвер инициирует операцию управления, обнуляет счетчик тайм-аута и возвращает
управление диспетчеру задач для постановки задачи на процессор действие 4.
По окончании обработки команды ввода-вывода устройство ввода-вывода выставляет сигнал запроса прерывания, по которому управление передается секции продолжения действие 5.
Получив новую команду, УВВ вновь ее обрабатывает, а управление процессором
вновь передаётся диспетчеру задач, и процессор продолжает вычисления. Таким
образом реализуется параллельная обработка задач, на фоне которой происходит
управление вводом-выводом.
4.8. Синхронный и асинхронный ввод вывод
Задача, выдавшая запрос на операцию ввода-вывода, переводится супервизором в состояние ожидания завершения заказанной операции. Когда супервизор получает от секции завершения сообщение о том, что операция завершилась, он переводит задачу в состояние готовности к выполнению, и она продолжает выполняться. Эта ситуация соответствует синхронному вводу-выводу. Синхронный ввод-вывод является стандартным для большинства операционных систем. Чтобы увеличить скорость выполнения приложений, было предложено при необходимости использовать асинхронный ввод-вывод.
Простейшим вариантом асинхронного вывода является так называемый
буферизованный вывод данных на внешнее устройство, при котором данные из
приложения передаются не непосредственно на устройство ввода-вывода, а в
специальный системный буфер — область памяти, отведенную для временного
размещения передаваемых данных. В этом случае логически операция вывода для
приложения считается выполненной сразу же, и задача может не ожидать окончания
действительного процесса передачи данных на устройство. Реальным выводом данных
из системного буфера занимается супервизор ввода-вывода. Естественно, что
выделение буфера из системной области памяти берет на себя специальный
системный процесс по указанию супервизора ввода-вывода. Итак, для
рассмотренного случая вывод будет асинхронным, если, во-первых, в запросе на
ввод-вывод указано на необходимость буферизации данных, а во-вторых, устройство
ввода-вывода допускает такие асинхронные операции, и это отмечено в UCB.
Можно организовать и асинхронный ввод данных. Однако для этого необходимо не
только выделять область памяти для временного хранения считываемых с устройства
данных и связывать выделенный буфер с задачей, заказавшей операцию, но и сам
запрос на операцию ввода-вывода разбивать на две части на два запроса, о первом
запросе указывается операция на считывание данных, подобно тому как это
делается при синхронном вводе-выводе, однако тип код запроса используется
другой, и в запросе указывается еще по крайней мере один дополнительный
Параметр — имя код системного объекта, которое получает задача в ответ на
запрос и которое идентифицирует выделенный буфер. Получив имя буфера будем ак
условно называть этот системный объект, хотя в различных операционных истемах
используются и другие термины, например класс, задача продолжает свою работу.
Здесь очень важно подчеркнуть, что в результате запроса на асинхронный ввод
данных задача не переводится супервизором ввода-вывода в состояние ожидания
завершения операции ввода-вывода, а остается в состоянии выполнения или в
состоянии готовности к выполнению. Через некоторое время выполнив необходимый
код, который был определен программистом, задача выдает второй запрос на
завершение операции ввода-вывода. В этом втором запросе к тому же устройству,
который, естественно, имеет другой код или имя запроса, задача указывает имя
системного объекта буфера для асинхронного ввода данных и в случае успешного
завершения операции считывания данных тут же получает их из системного буфера.
Если же данные еще не успели до конца переписаться с внешнего устройства в
системный буфер, супервизор ввода-вывода переводит задачу в состояние ожидания
завершения операции ввода-вывода, и далее все напоминает обычный синхронный
ввод данных.
Асинхронный ввод-вывод характерен для большинства мультипрограммных операционных систем, особенно если операционная система поддерживает мультизадачность с помощью механизма потоков выполнения. Однако если асинхронный ввод-вывод в явном виде отсутствует, его можно реализовать самому, организовав для вывода данных отдельный поток выполнения.
Аппаратуру ввода-вывода можно рассматривать как совокупность аппаратных процессоров, которые способны работать параллельно друг другу, а также параллельно центральному процессору процессорам. На таких процессорах выполняются так называемые внешние процессы. Например, для печатающего устройства внешнее устройство вывода данных внешний процесс может представлять собой совокупность операций, обеспечивающих перевод печатающей головки, продвижение бумаги на одну позицию, смену цвета чернил или печать каких-то символов. Внешние процессы, используя аппаратуру ввода-вывода, взаимодействуют как между собой, так и с обычными программными процессами, выполняющимися на центральном процессоре. Важным при этом является обстоятельство, что скорости выполнения внешних процессов будут существенно порой на порядок или больше отличаться от скорости выполнения обычных {внутренних процессов. Для своей нормальной работы внешние и внутренние процессы обязательно должны синхронизироваться. Для сглаживания эффекта значительного несоответствия скоростей между внутренними и внешними процессами используют упомянутую выше буферизацию. Таким образом, можно говорить о системе параллельных взаимодействующих процессов см. главу 7.
Буферы буфер являются критическим ресурсом в отношении внутренних программных и внешних процессов, которые при параллельном своем развитии информационно взаимодействуют. Через буферы данные либо посылаются от некоторого процесса к адресуемому внешнему операция вывода данных на внешнее устройство, либо от внешнего процесса передаются некоторому программному процессу операция считывания данных. Введение буферизации как средства информационного взаимодействия выдвигает проблему управления этими системными буферами, которая решается средствами супервизорной части операционной системы. При этом на супервизор возлагаются задачи не только по выделению и освобождению буферов в системной области памяти, но и по синхронизации процессов в соответствии с состоянием операций заполнения или освобождения буферов, а также по их ожиданию, если свободных буферов в наличии нет, а запрос на ввод-вывод требует буферизации. Обычно супервизор ввода-вывода для решения перечисленных задач использует стандартные средства синхронизации, принятые в данной операционной системе. Поэтому если операционная система имеет развитые средства для решения проблем параллельного выполнения взаимодействующих приложений и задач, то, как правило, она реализует и асинхронный ввод-вывод.
4.9. Организация внешней памяти на магнитных дисках
Магнитные диски представляют собой пакеты магнитных пластин поверхностей,
между которыми на одном рычаге двигается пакет магнитных головок рис. 1.1. Шаг
движения пакета головок является дискретным, и каждому положению пакета головок
логически соответствует цилиндр пакета магнитных дисков. На каждой поверхности
цилиндр высекает дорожку, так что каждая поверхность содержит число дорожек,
равное числу цилиндров. При разметке магнитного диска специальном действии,
предшествующем использованию диска каждая дорожка размечается на одно и то же
количество блоков; таким образом, предельная емкость каждого блока составляет
одно и то же число байтов. Для задания обмена с магнитным диском на уровне
аппаратуры нужно указать номер цилиндра, номер поверхности, номер блока на
соответствующей дорожке и число байтов, которое нужно записать или прочитать от
начала этого блока.
Рис. 1.1. Грубая схема дискового устройства памяти с подвижными головками
При выполнении обмена с диском аппаратура выполняет три основных действия:
подвод головок к нужному цилиндру обозначим время выполнения этого действия как
tпг, поиск на дорожке нужного блока время выполнения — tпб и собственно обмен с
этим блоком время выполнения — tоб. Тогда, как правило, tпгtпбtоб , потому что
подвод головок — это механическое действие, причем в среднем нужно переместить
головки на расстояние, равное половине радиуса поверхности, а скорость
передвижения головок не может быть слишком большой по физическим соображениям.
Поиск блока на дорожке требует прокручивания пакета магнитных дисков в среднем
на половину длины внешней окружности; скорость вращения диска может быть
существенно больше скорости движения головок, но она тоже ограничена законами
физики. Для выполнения же собственно чтения или записи нужно прокрутить пакет
дисков всего лишь на угловое расстояние, соответствующее размеру блока. Таким
образом, из всех этих действий в среднем наибольшее время занимает первое, и
поэтому существенный выигрыш в суммарном времени обмена при считывании или
записи только части блока получить практически невозможно.
С появлением магнитных дисков началась история систем управления данными во
внешней памяти. До этого каждая прикладная программа, которой требовалось
хранить данные во внешней памяти, сама определяла расположение каждой порции
данных на магнитной ленте или барабане и выполняла обмены между оперативной и
внешней памятью с помощью программно-аппаратных средств низкого уровня машинных
команд или вызовов соответствующих программ операционной системы. Такой режим
работы не позволял или очень затруднял поддержание на одном внешнем носителе
нескольких архивов долговременно хранимой информации. Кроме того, каждой
прикладной программе приходилось решать проблемы именования частей данных и
структуризации данных во внешней памяти.
4.10. Кэширование операций ввода вывода при работе с накопителями на магнитных дисках
Как известно, накопители на магнитных дисках обладают крайне низкой скоростью по сравнению с быстродействием центральной части компьютера. Разница в быстродействии отличается на несколько порядков. Например, современные процессоры за один такт работы, а они работают уже с частотами в 1 ГГц и более, могут выполнять по две операции. Таким образом, время выполнения операции с позиции внешнего наблюдателя, не видящего конвейеризации при выполнении, машинных команд, благодаря которой производительность возрастает в несколько раз может составлять 0,5 нс !. В то же время переход магнитной головки с дорожки на дорожку составляет несколько миллисекунд. Такие же временные интервалы имеют место и при ожидании, пока под головкой чтения записи не окажется нужный сектор данных. Как известно, в современных приводах средняя длительность на чтение случайным образом выбранного сектора данных составляет около 20 мс, что существенно медленнее, чем выборка команды или операнда из оперативной памяти и уж тем более из кэша. Правда, после этого данные читаются большим пакетом сектор, как мы уже говорили, имеет размер в 512 байтов, а при операциях с диском часто читается или записывается сразу несколько секторов. Таким образом, средняя скорость работы процессора с оперативной памятью на 2-3 порядка выше, чем средняя скорость передачи данных из внешней памяти на магнитных дисках в оперативную память.
Для того чтобы сгладить такое сильное несоответствие в производительности основных подсистем, используется буферирование иили кэширование данных. Простейшим вариантом ускорения дисковых операций чтения данных можно считать использование двойного буферирования. Его суть заключается в том, что пока в один буфер заносятся данные с магнитного диска, из второго буфера ранее считанные данные могут быть прочитаны и переданы запросившей их задаче. Аналогичный процесс происходит и при записи данных. Буферирование используется во всех операционных системах, но помимо буферирования применяется и кэширование. Кэширование исключительно полезно в том случае, когда программа неоднократно читает с диска одни и те же данные. После того как они один раз будут помещены в кэш, обращений к диску больше не потребуется и скорость работы программы значительно возрастет.
Если не вдаваться в подробности, то под кэшем можно понимать некий пул буферов, которыми мы управляем с помощью соответствующего системного процесса. Если мы считываем какое-то множество секторов, содержащих записи того или иного файла, то эти данные, пройдя через кэш, там остаются до тех пор, пока другие секторы не заменят эти буферы. Если впоследствии потребуется повторное чтение, то данные могут быть извлечены непосредственно из оперативной памяти без фактического обращения к диску. Ускорить можно и операции записи: данные помещаются в кэш, и для запросившей эту операцию задачи можно считать, что они уже фактически и записаны. Задача может продолжить свое выполнение, а системные внешние процессы через некоторое время запишут данные на диск. Это называется операцией отложенной записи lazy write, ленивая запись. Если отложенная запись отключена, только одна задача может записывать на диск свои данные. Остальные приложения должны ждать своей очереди. Это ожидание подвергает информацию риску не меньшему если не большему, чем отложенная запись, которая к тому же и более эффективна по скорости работы с диском.
Интервал времени, после которого данные будут фактически записываться, с одной стороны, желательно выбрать больше, поскольку если потребуется еще раз прочитать эти данные, то они уже и так фактически находятся в кэше. И после модификации эти данные опять же помещаются в быстродействующий кэш. С другой стороны, для большей надежности данные желательно поскорее отправить во внешнюю память, поскольку она энергонезависима и в случае какой-нибудь аварии например, нарушения питания данные в оперативной памяти пропадут, в то время как на магнитном диске они с большой вероятностью останутся в безопасности. Количество буферов, составляющих кэш, ограничено, поэтому возникает ситуация, когда вновь прочитанные или записываемые новые секторы данных должны будут заменить данные в этих буферах. Возможно использование различных дисциплин, в соответствии с которыми будет назначен какой-либо буфер под вновь затребованную операцию кэширования.
Кэширование дисковых операций может быть существенно улучшено за счет введения техники упреждающего чтения read ahead. Она основана на чтении с диска гораздо большего количества данных, чем на самом деле запросила операционная система или приложение. Когда некоторой программе требуется считать с диска только один сектор, программа кэширования читает еще и несколько дополнительных блоков данных. А операции последовательного чтения нескольких секторов фактически несущественно замедляют операцию чтения затребованного сектора с данными. Поэтому, если программа вновь обратится к диску, вероятность того, что нужные ей данные уже находятся в кэше, достаточно высока. Поскольку передача данных из одной области памяти в другую происходит во много раз быстрее, чем чтение их с диска, кэширование существенно сокращает время выполнения операций с файлами.
Итак, путь информации от диска к прикладной программе пролегает как через буфер, так и через файловый кэш. Когда приложение запрашивает с диска данные, программа кэширования перехватывает этот запрос и читает вместе с необходимыми секторами еще и несколько дополнительных. Затем она помещает в буфер требующуюся задаче информацию и ставит об этом в известность операционную систему. Операционная система сообщает задаче, что ее запрос выполнен и данные с диска находятся в буфере. При следующем обращении приложения к диску программа кэширования прежде всего проверяет, не находятся ли уже в памяти затребованные данные. Если это так, то она копирует их в буфер; если же их в кэше нет, то запрос на чтение диска передается операционной системе. Когда задача изменяет данные в буфере, они копируются в кэш.
В ряде ОС имеется возможность указать в явном виде параметры кэширования, в то время как в других за эти параметры отвечает сама ОС. Так, например, в системе Windows NT нет возможности в явном виде управлять ни объемом файлового кэша, ни параметрами кэширования. В системах Windows 9598 такая возможность уже имеется, но она представляет не слишком богатый выбор. Фактически мы можем указать только объем памяти, отводимый для кэширования, и объем порции данных буфер или chunk, из которых набирается кэш. В файле System.ini есть возможность в секции [VCACHE] прописать, например, следующие значения:
[vcache]
MinFileCache=4096
MaxFileCache-32768
ChunkSize=512
Здесь указано, что минимально под кэширование данных зарезервировано 4 Мбайт оперативной памяти, максимальный объем кэша может достигать 32 Мбайт, а размер данных, которыми манипулирует менеджер кэша, равен одному сектору.
В других ОС можно указывать больше параметров, определяющих работу подсистемы кэширования.
Помимо описанных действий ОС может выполнять и работу по оптимизации перемещения головок чтениязаписи данных, связанного с выполнением запросов от параллельно выполняющихся задач. Время, необходимое на получение данных с магнитного диска, складывается из времени перемещения магнитной головки на требуемый цилиндр и времени ожидания заданного сектора; временем считывания найденного сектора и затратами на передачу этих данных в оперативную память мы можем пренебречь. Таким образом, основные затраты времени уходят на поиск данных. В мультипрограммных ОС при выполнении многих задач запросы на чтение и запись данных могут идти таким потоком, что при их обслуживании образуется очередь. Если выполнять эти запросы в порядке поступления их в очередь, то вследствие случайного характера обращений к тому или иному сектору магнитного диска мы можем иметь значительные потери времени на поиск данных. Напрашивается очевидное решение: поскольку выполнение переупорядочивания запросов с целью минимизации затрат времени на поиск данных можно выполнить очень быстро практически этим временем можно пренебречь, учитывая разницу в быстродействии центральной части и устройств ввода-вывода, то необходимо найти метод, позволяющий перестраивать очередь запросов оптимальным образом. Изучение этой проблемы позволило найти наиболее эффективные дисциплины планирования.
Перечислим известные дисциплины, в соответствии с которыми можно перестраивать очередь запросов на операции чтения записи данных:
STF shortest seek time — first — с наименьшим временем поиска — первым. В соответствии с этой дисциплиной при позиционировании магнитных головок следующим выбирается запрос, для которого необходимо минимальное перемещение с цилиндра на цилиндр, даже если этот запрос не был первым в очереди на вводвывод. Однако для этой дисциплины характерна резкая дискриминация определенных запросов, а ведь они могут идти от высокоприоритетных задач. Обращения к диску проявляют тенденцию концентрироваться, в результате чего запросы на обращение к самым внешним и самым внутренним дорожкам могут обслуживаться. Существенно дольше и нет никакой гарантии обслуживания. Достоинством такой дисциплины является максимально возможная пропускная способность дисковой подсистемы.
can сканирование. По этой дисциплине головки перемещаются то в одном, то в другом привилегированном направлении, обслуживая по пути подходящие запросы. Если при перемещении головок чтения-записи более нет попутных запросов, то движение начинается в обратном направлении.
ext-Step Scan — отличается от предыдущей дисциплины тем, что на каждом проходе обслуживаются только запросы, которые уже существовали на момент начала прохода. Новые запросы, появляющиеся в процессе перемещения головок чтениязаписи, формируют новую очередь запросов, причем таким образом, чтобы их можно было оптимально обслужить на обратном ходу.
C-Scan циклическое сканирование. По этой дисциплине головки перемещаются циклически с самой наружной дорожки к внутренним, по пути обслуживая имеющиеся запросы, после чего вновь переносятся к наружным цилиндрам. Эту дисциплину иногда реализуют таким образом, чтобы запросы, поступающие во время текущего прямого хода головок, обслуживались не попутно, а при следующем ходе, что позволяет исключить дискриминацию запросов к самым крайним цилиндрам; она характеризуется очень малой дисперсией времени ожидания обслуживания. Эту дисциплину обслуживания часто называют элеваторной.
5.
Принципы построения и классификация
5.1. Принципы построения
Принцип модульности
Модуль — функционально значимый элемент системы, обладающий установленным
межмодульным интерфейсом. Последний предполагает возможность замены его любым
другим модулем, обладающим таким же интерфейсом.
Принцип модульности даёт максимальный эффект, если он распространяется на ОС,
прикладные программы и аппаратуру.
Принцип функциональной избирательности
Некоторая часть модулей ОС должна частично находиться в памяти для более
эффективной организации вычислительного процесса. Она называется ядром ОС. К
ядру предъявляются требования минимальности требуемого объема памяти и наиболее
часто используемым функциям. К ядру, как правило, относят модули управления
системой прерываний, управления задачами, модули управления ресурсами.
Остальные модули ОС называются транзитными или диск-резидентными. Они
загружаются в память по необходимости, а при отсутствии свободного пространства
памяти замещаются другими, более необходимыми в данный момент.
Принцип генерируемости
Суть его в том, что способ исходного представления ядра ОС должен позволять
настройку его на непосредственную конфигурацию вычислительного комплекса на
круг решаемых задач. Процесс генерации осуществляется программой генерации ОС с
использованием соответствующего программного языка, позволяющего описывать
программные возможности системы и конфигурацию машины. В результате
генерируется полная рабочая версия ОС.
Использование принципа модульности упрощает настройку ОС.
В большинстве современных ОС для персональных компьютеров конфигурирование под
имеющийся состав оборудования производится на этапе инсталляции, а последующие
изменения параметров ОС или состава драйверов производятся редактированием
файла конфигурации.
Единственной ОС, генерируемой в полном смысле является ОС Linux. В ней можно
сгенерировать ядро, оптимальное для данного компьютера и указать набор
подгружаемых драйверов и служб.
Принцип функциональной избыточности
Он учитывает возможность выполнения одной и той же работы различными
средствами. Наличие возможности использования нескольких типов мониторов или
планировщиков ресурсов, систем управления файлами и т.д. позволяет быстро и
адекватно адаптировать ОС к данной конфигурации вычислительной системы,
эффективно загружать технические средства, получить максимальную
производительность.
Принцип виртуализации
Он позволяет представить структуру системы в виде набора планировщиков
процессов и распределителей ресурсов и использовать единую схему распределения
ресурсов. Наиболее полно принцип проявляется в понятии виртуальной машины
машины вообще, обладающей идеальными для пользователя архитектурными
характеристиками:
- единая т.е. виртуальная память неограниченного объема со временем доступа, совпадающим с аналогичным параметром реальной машины
- произвольное количество процессов виртуальных способных работать с памятью параллельно и последовательно, синхронно и асинхронно способ выбирается пользователем
- произвольное число внешних устройств с неограниченными объёмами хранимой информации с различными видами доступа и открытой архитектурой.
Степень приближения реальной машины и виртуальной может быть больше или
меньше в каждом конкретном случае.
Одним из примеров применения принципа виртуальности является имеющаяся во всех
ОС Windows, OS2 VDM-машина virtual DOS-machine — защищенная подсистема,
предоставляющая полную MS-DOS среду и консоль для выполнения DOS-приложений.
Принцип независимости программ от внешних устройств
Суть его в том, что связь программы с внешним устройством устанавливается не на
этапе трансляции, а в период планирования её исполнения. Программа общается не
с устройствами, а с ОС, сообщая ей о потребности в ресурсах для выполнения
данной работы. Конкретное устройство, на котором эта работа будет выполнена,
программу не интересует, это задача ОС.
Принцип совместимости
Суть принципа — в обеспечении способности ОС выполнять программы, написанные
для других ОС или под другие аппаратные платформы.
Различают совместимость на уровне исходных текстов текстовая совместимость и на
уровне кодов двоичная совместимость.
Первая требует наличия транслятора, совместимость на уровне библиотек и
системных вызовов. При этом требуется повторная компиляция исходных текстов в
новый исполняемый модуль.
Вторая требует совместимость на уровне архитектуры процессоров и систем команд.
Для реализации такой совместимости используются эмуляторы прикладные среды.
Принцип открытости и наращиваемости
Открытая ОС доступна для анализа пользователем и системным программистом.
Наращиваемая ОС позволяет вводить в состав новые модули, модернизировать
существующие и т.д., не нарушая целостности системы. Пример наращиваемости
демонстрируют структурированные ОС типа клиент-сервер на основе микроядерной
технологии, когда ядро системы привилегированная управляющая программа сохраняется
неизменяемым, а состав серверов набор непривилегированных услуг может
модифицироваться. Примером открытой системы является ОС Linux и
всеUNIX-системы.
Принцип мобильности переносимости
Принцип требует, чтобы ОС легко устанавливалась с одного процессора на другой,
с одной аппаратной платформы на другую. Для этого ОС в основном должна быть
написана на языке, имеющемся на всех платформах, куда её планируется переносить
предпочтительно на С. Кроме того, в ней должны быть минимизированы а ещё лучше
— исключены средства взаимодействия с аппаратурой. Не исключенные аппаратно
зависимые части кода должны быть изолированы в хорошо локализируемых модулях.
Тогда при переносе меняются или подстраиваются только эти локальные данные и
функции взаимодействия с ними.
Принцип безопасности вычислений
Правила безопасности защищают ресурсы одного пользователя от других и
устанавливают квоты на ресурсы для предотвращения захвата всех ресурсов одним
пользователем.
Основы стандартов в области безопасности вычислений были заложены в документе
под названием Критерии оценки наземных компьютерных систем и изданном
Национальным центром компьютерной безопасности США NCSC — National Computer
Security Center в
Определено 4 уровня безопасности А высший — D низший. При этом в класс D
попадают системы, у которых выявлено несоответствие всем трём высшим классам.
Класс С делится на два уровня: С1 обеспечивает защиту данных от ошибок
пользователя, но не от злоумышленников, а С2 защищает данные в обоих ситуациях.
На уровне С2 должны присутствовать:
- секретность входа идентифицируя пользователей по уникальному имени и паролю
- контроль доступа информирование владельца данных о лицах, имеющих доступ к данным и их правах на пользование ими
- наблюдение и учет за ситуацией с безопасностью фиксация попыток получить доступ, создать или удалить системные реестры
- защита памяти удаление содержимого памяти предыдущего сеанса работы перед
началом нового.
Системы уровня В реализуют контроль доступа каждый пользователь имеет рейтинг
защиты и доступ только в соответствии с этим рейтингом. Эти системы защищены от
ошибочного поведения пользователя.
Уровень А требует дополнительно формального, математически доказанного
соответствия системы требованиям безопасности. Однако А-уровень занимает своими
управляющими механизмами до 90% процессорного времени. Более безопасные системы
не только снижают продуктивность, но и ограничивают число доступных приложений.
Различные коммерческие структуры, например банки, поддерживают безопасность
своих систем, как правило на уровне С2.
5.2. Ядро и ресурсы
Ядро — центральная часть операционной системы ОС, обеспечивающая приложениям
координированный доступ к ресурсам компьютера, таким как процессорное время,
память, внешнееаппаратное обеспечение, внешнее устройство ввода и вывода
информации. Также обычно ядро предоставляет сервисы файловой системы и сетевых
протоколов.
Как основополагающий элемент ОС, ядро представляет собой наиболее низкий
уровень абстракции для доступа приложений к ресурсам системы, необходимым для
их работы. Как правило, ядро предоставляет такой доступ исполняемым процессам
соответствующих приложений за счёт использования механизмов межпроцессного
взаимодействия и обращения приложений к системным вызовам ОС.
Описанная задача может различаться в зависимости от типа архитектуры ядра и
способа её реализации.
5.3. Интерфейсы ОС
Напомним, что операционная система всегда выступает как интерфейс между
аппаратурой компьютера и пользователем с его задачами. Под интерфейсами
операционных систем здесь и далее следует понимать специальные интерфейсы
системного и прикладного программирования API, предназначенные для выполнения
перечисленных ниже задач.
• Управление процессами, которое включает в себя следующий набор основных
функций:
• запуск, приостанов и снятие задачи с выполнения
• задание или изменение приоритета задачи
• взаимодействие задач между собой механизмы сигналов, семафорные примитивы, очереди, конвейеры, почтовые ящики
• вызов удаленных процедур Remote Procedure Call, RPC.
• Управление памятью:
• запрос на выделение блока памяти
• освобождение памяти
• изменение параметров блока памяти например, память может быть заблокирована процессом либо предоставлена в общий доступ
• отображение файлов на память имеется не во всех системах.
• Управление вводом-выводом:
• запрос на управление виртуальными устройствами напомним, что управление
вводом-выводом является привилегированной функцией самой операционной системы,
и никакая из пользовательских задач не должна иметь возможности непосредственно
управлять устройствами
• файловые операции запросы к системе управления файлами на создание, изменение и удаление данных, организованных в файлы.
Здесь мы перечислили основные наборы функций, которые выполняются
операционной системой по соответствующим запросам от задач. Что касается
интерфейса пользователя с операционной системой, то он реализуется с помощью
специальных программных модулей, которые принимают его команды на
соответствующем языке возможно, с использованием графического интерфейса и
транслируют их в обычные вызовы в соответствии с основным интерфейсом системы.
Обычно эти модули называют интерпретатором команд. Так, например, функции
такого интерпретатора в MS DOS выполняет модуль CDMMAND.COM. Получив от
пользователя команду, такой модуль после лексического и синтаксического анализа
либо сам выполняет действие, либо, что случается чаще, обращается к другим
модулям операционной системы, используя механизм API. Надо заметить, что в
последние годы большую популярность получили графические интерфейсы Graphical
User Interface, GUI, в которых задействованы соответствующие манипуляторы типа
мышь или трекбол track-ball1. Указание курсором на объект и щелчок или двойной
щелчок на соответствующей кнопке мыши приводит к каким-либо действиям — запуску
программы, ассоциированной с объектом, выбору иили активизации меню и т. д.
Можно сказать, что такая интерфейсная подсистема транслирует команды
пользователя в обращения к операционной системе.
Поясним также, что управление GUI является частным случаем задачи управления
вводом-выводом и не относится к функциям ядра операционной системы, хотя в ряде
случаев разработчики операционной системы относят функции GUI к основному
системному интерфейсу API.
Следует отметить, что имеются два основных подхода к управлению задачами. Так,
в одних системах порождаемая задача наследует все ресурсы задачи-родителя,
тогда как в других системах существуют равноправные отношения, и при порождении
нового процесса ресурсы для него запрашиваются у операционной системы.
Обращения к операционной системе в соответствии с имеющимся интерфейсом API
могут осуществляться как посредством вызова подпрограммы с передачей ей
необходимых параметров, так и через механизм программных прерываний. Выбор
метода реализации вызовов функций API должен определяться архитектурой
платформы.
5.4. Классификация ОС
Существуют различные виды классификации ОС по тем или иным признакам,
отражающие разные существенные характеристики систем.
По назначению.
Системы общего назначения. Это достаточно расплывчатое название подразумевает
ОС, предназначенные для решения широкого круга задач, включая запуск различных
приложений, разработку и отладку программ, работу с сетью и с мультимедиа.
Системы реального времени. Этот важный класс систем предназначен для работы в
контуре управления объектами такими, как летательные аппараты, технологические
установки, автомобили, сложная бытовая техника и т.п.. Из подобного назначения
вытекают жесткие требования к надежности и эффективности системы. Должно быть
обеспечено точное планирование действий системы во времени управляющие сигналы
должны выдаваться в заданные моменты времени, а не просто по возможности
быстро. Особый подкласс составляют системы, встроенные в оборудование. Такие
системы годами могут выполнять фиксированный набор программ, не требуя
вмешательства человека-оператора на более глубоком уровне, чем нажатие кнопки
Вкл..
Иногда выделяют также такой класс ОС, как системы с нежестким реальным
временем. Это такие системы, которые не могут гарантировать точное соблюдение
временных соотношений, но очень стараются, т.е. содержат средства для
приоритетного выполнения заданий, критичных по времени. Такой системе нельзя
доверить управление ракетой, но она вполне справится с демонстрацией
видеофильма. Выделение подобных систем в отдельный класс имеет скорее рекламное
значение, позволяя таким системам, как Windows NT и некоторые версии UNIX, тоже
называть себя системами реального времени.
Прочие специализированные системы. Это различные ОС, ориентированные прежде
всего на эффективное решение задач определенного класса, с большим или меньшим
ущербом для прочих задач. Можно выделить, например, сетевые системы такие, как
Novell Netware, обеспечивающие надежное и высокоэффективное функционирование
локальных сетей.
По характеру взаимодействия с пользователем.
Пакетные ОС, обрабатывающие заранее подготовленные задания.
Диалоговые ОС, выполняющие команды пользователя в интерактивном режиме.
Красивое слово интерактивный означает постоянное взаимодействие системы с
пользователем.
ОС с графическим интерфейсом. В принципе, их также можно отнести к диалоговым
системам, однако использование мыши и всего, что с ней связано меню, кнопки и
т.п. вносит свою специфику.
Встроенные ОС, не взаимодействующие с пользователем.
По числу одновременно выполняемых задач.
Однозадачные ОС. В таких системах в каждый момент времени может существовать не
более чем один активный пользовательский процесс. Следует заметить, что
одновременно с ним могут работать системные процессы например, выполняющие
запросы на вводвывод.
Многозадачные ОС. Они обеспечивают параллельное выполнение нескольких
пользовательских процессов. Реализация многозадачности требует значительного
усложнения алгоритмов и структур данных, используемых в системе.
По числу пользователей.
Однопользовательские ОС. Для них характерен полный доступ пользователя к
ресурсам системы. Подобные системы приемлемы в основном для изолированных
компьютеров, не допускающих доступа к ресурсам данного компьютера по сети или с
удаленных терминалов.
Многопользовательские ОС. Их важной компонентой являются средства защиты данных
и процессов каждого пользователя, основанные на понятии владельца ресурса и на
точном указании прав доступа, предоставленных каждому пользователю системы.
По аппаратурной основе.
Однопроцессорные ОС. В данном курсе будут рассматриваться только они.
Многопроцессорные ОС. В задачи такой системы входит, помимо прочего,
эффективное распределение выполняемых заданий по процессорам и организация
согласованной работы всех процессоров.
Сетевые ОС. Они включают возможность доступа к другим компьютерам локальной сети,
работы с файловыми и другими серверами.
Распределенные ОС. Их отличие от сетевых заключается в том, что распределенная
система, используя ресурсы локальной сети, представляет их пользователю как
единую систему, не разделенную на отдельные машины.
6. Защита от сбоев и несанкционированного доступа
6.1. Анализ угроз и уязвимостей ОС
Одновременно с развитием систем информационных технологий развиваются и
угрозы безопасности, с которыми им приходится сталкиваться. При определении
угрозы безопасности особое внимание обращается на два основных фактора:
типы нападений, с которыми, вероятно, придется столкнуться
где эти нападения могут произойти.
Большинство организаций пренебрегают вторым фактором, предполагая, что серьезное нападение может происходить только извне в основном через соединение с Интернет. В исследовании Службы безопасности и компьютерных преступлений, совместно проведенном Институтом компьютерной безопасности CSI и Федеральным Бюро Расследований США 31 % респондентов отметили свои внутренние системы как наиболее частый объект нападения. Тем не менее, множество компаний могут просто не осознавать, что нападения изнутри происходят, главным образом потому, что их никто не отслеживает и не контролирует.
Для управления безопасностью предприятия оцениваются риски, с которыми придется столкнуться, определяется приемлемый уровень риска, и он сохранятся на своем уровне или ниже. Риски уменьшаются путем увеличения степени безопасности среды.
В процессе управления рисками используются следующие понятия: ресурсы, угрозы, уязвимые места, эксплуатации и контрмеры.
Угроза — это человек, место или вещь, которые имеют возможность получить доступ к ресурсам и причинить вред. Угрозы подразделяются на:
· природные и физические
· непреднамеренные
· намеренные.
Уязвимое место — это место, где ресурс наиболее восприимчив
к нападению, слабости определенного рода.
Уязвимые места по виду подразделяются на:
1. физические
2. природные
3. оборудование и программное обеспечение
4. носители
5. связь
6. человек.
ОС, как ресурс, может оказаться доступной для угрозы, использующей ее уязвимость. Данный тип нападения известен как эксплуатация. Эксплуатация ресурсов может быть достигнута многими способами. Когда потенциальная угроза использует уязвимые места нападения на ресурс, последствия могут быть очень серьезными.
Контрмеры применяются с целью противодействия угрозам и уязвимости, сокращая риск среды.
Таким образом, одним из способов обеспечения безопасности и уменьшения риска ОС является тщательная проверка на вторжения и взломы.
Имеется множество оснований для того, чтобы считать очень важными аудит и
обнаружение вторжений в ОС:
любая функциональная компьютерная среда может подвергнуться нападению. Сколь бы
ни был высок уровень защиты, риск вторжения существует всегда
за несколькими неудачными попытками вторжения часто следует удачные. Если не стоит программа отслеживания вторжений, невозможно будет засечь неудачные попытки взлома до того, как состоится удачная
если же попытка взлома заканчивается удачно — чем раньше об этом станет известно, тем легче будет ограничить возможный вред
чтобы восстановиться от повреждений после вторжения, необходимо знать, какой вред был нанесен
аудит и обнаружение вторжений помогут определить, кто несет ответственность за нападение
сочетание аудита и обнаружения вторжений помогает соотносить информацию и идентифицировать схему вторжения
регулярный обзор системных журналов безопасности помогает идентифицировать нерешенные вопросы конфигурации безопасности — в частности, неверные права доступа, или неопределенные настройки локаута учетной записи
после обнаружения взлома аудит может помочь определить, какие ресурсы сети были повреждены.
Средства мониторинга событий вторжения и безопасности, включенные в состав ОС, включает как пассивные, так и активные задачи. После нападения многие вторжения обнаруживаются с помощью инспекции файлов системного журнала. Такое обнаружение, происходящее по факту совершения нападения, часто называют пассивным обнаружением вторжения.
Другие попытки вторжения могут обнаруживаться собственно во время нападения. Этот метод, известный как активное обнаружение нападения, ищет известные схемы нападений, или команды, и блокирует исполнение этих команд.
6.2. Основы криптографии
Цель криптографической системы заключается в том, чтобы зашифровать
осмысленный исходный текст также называемый открытым текстом, получив в
результате совершенно бессмысленный на взгляд шифрованный текст шифртекст,
криптограмма. Получатель, которому он предназначен, должен быть способен
расшифровать говорят также дешифровать этот шифртекст, восстановив, таким
образом, соответствующий ему открытый текст. При этом противник называемый
также криптоаналитиком должен быть неспособен раскрыть исходный текст.
Существует важное отличие между расшифрованием дешифрованием и раскрытием
шифртекста.
Раскрытием криптосистемы называется результат работы криптоаналитика,
приводящий к возможности эффективного раскрытия любого, зашифрованного с
помощью данной криптосистемы, открытого текста. Степень неспособности
криптосистемы к раскрытию называется ее стойкостью.
Вопрос надёжности систем ЗИ — очень сложный. Дело в том, что не существует
надёжных тестов, позволяющих убедиться в том, что информация защищена
достаточно надёжно. Во-первых, криптография обладает той особенностью, что на
вскрытие шифра зачастую нужно затратить на несколько порядков больше средств,
чем на его создание. Следовательно тестовые испытания системы криптозащиты не
всегда возможны. Во-вторых, многократные неудачные попытки преодоления защиты
вовсе не означают, что следующая попытка не окажется успешной. Не исключён
случай, когда профессионалы долго, но безуспешно бились над шифром, а некий
новичок применил нестандартный подход — и шифр дался ему легко.
В результате такой плохой доказуемости надёжности средств ЗИ на рынке очень
много продуктов, о надёжности которых невозможно достоверно судить.
Естественно, их разработчики расхваливают на все лады своё произведение, но
доказать его качество не могут, а часто это и невозможно в принципе. Как
правило, недоказуемость надёжности сопровождается ещё и тем, что алгоритм
шифрования держится в секрете.
На первый взгляд, секретность алгоритма служит дополнительному обеспечению
надёжности шифра. Это аргумент, рассчитанный на дилетантов. На самом деле, если
алгоритм известен разработчикам, он уже не может считаться секретным, если
только пользователь и разработчик — не одно лицо. К тому же, если вследствие
некомпетентности или ошибок разработчика алгоритм оказался нестойким, его
секретность не позволит проверить его независимым экспертам. Нестойкость
алгоритма обнаружится только когда он будет уже взломан, а то и вообще не
обнаружится, ибо противник не спешит хвастаться своими успехами.
Поэтому криптограф должен руководствоваться правилом, впервые сформулированным
голландцем Керкхоффом: стойкость шифра должна определяться только секретностью
ключа. Иными словами, правило Керкхоффа состоит в том, что весь механизм
шифрования, кроме значения секретного ключа априори считается известным
противнику.
Другое дело, что возможен метод ЗИ строго говоря, не относящийся к
криптографии, когда скрывается не алгоритм шифровки, а сам факт того, что
сообщение содержит зашифрованную скрытую в нём информацию. Такой приём
правильнее назвать маскировкой информации
6.3. Механизмы защиты
Механизмы защиты должны обеспечивать ограничение доступа субъектов к
объектам: во-первых, доступ к объекту должен быть разрешен только для
определенных субъектов, во-вторых, даже имеющему доступ субъекту должно быть
разрешено выполнение только определенного набора операций.
Для обеспечения защиты могут применяться следующие механизмы:
· кодирование объектов
· сокрытие местоположения объектов
· инкапсуляция объектов.
Кодирование предполагает шифрование информации, составляющей объект. Любой
субъект может получить доступ к информации, но воспользоваться ею может лишь
привилегированный субъект, знающий ключ к коду. Другой вариант защиты через
кодирование предполагает, что расшифровка информации производится системными
средствами, но только для привилегированных субъектов. Кодирование не защищает
объект от порчи, поэтому оно может использоваться только для защиты узкого
класса специфических объектов или в качестве дополнительного средства в
сочетании с другими механизмами защиты. Рассмотрение способов кодирования не
входит в задачи нашего пособия, оно должно происходить при изучении курса
Защита информации.
Сокрытие местоположения объекта предполагает, что адрес объекта в памяти
системы известен только тем субъектам, которые имеют право доступа к объекту.
Такие привилегированные субъекты могут выполнять любые операции над объектом.
Непривилегированные субъекты могут запрашивать доступ к объекту и получать
некий внутренний идентификатор объекта. Используя этот идентификатор, они могут
выполнять над объектом ограниченный набор операций, но не непосредственно, а
обращаясь к привилегированным субъектам. Примером такого механизма является
сокрытие дескрипторов ресурсов. Местоположение адрес в памяти дескрипторов
известно ОС, прикладные же процессы получают манипулятор ресурса, который, как
правило, адресует дескриптор только косвенно через таблицы. Если сокрытие
является единственным механизмом защиты, то защиту нельзя назвать
непроницаемой. Субъект может получить адрес объекта случайно или намеренно
получив доступ к внутренней документации.
Инкапсуляция предполагает полное закрытие для субъектов возможности
оперирования с внутренним содержимым объектов. Субъект даже не должен знать
структуры этого содержимого. Для каждого объекта, однако, определено множество
допустимых операций над ним, которые реализуются монитором объекта. Объект,
таким образом, предстает в виде черного ящика с четко специфицированными
входами и выходами и с абсолютно непроницаемыми стенками. Механизм инкапсуляции
может обеспечивать наиболее полную защиту, но его реализация требует решения
двух важных вопросов: во-первых, как обеспечить непрозрачность стенок,
во-вторых, как принимать решения о предоставлении доступа или об отказе в нем.
Непроницаемость ящика обеспечивается чаще всего средствами защиты памяти.
Область памяти, в которой расположен объект, делается недоступной для любых
субъектов, кроме монитора, реализующего операции над объектом. Как мы знаем см.
главу 3, защита памяти поддерживается аппаратными средствами вычислительных
систем, и защита объектов, таким образом, представляется реализованной на
аппаратном уровне. Надежность такой защиты, однако, в значительной степени
иллюзорна. Во-первых, память также представляет собой объект, нуждающийся в
защите. От того, насколько сама защита памяти защищена от перепрограммирования ее
произвольным субъектом, зависит эффективность всей системы защиты в целом.
Во-вторых, аппаратно поддерживается только конечное число уровней защиты
памяти, на практике же используются только два уровня: доступ к ограниченному
подмножеству адресов и полный доступ. Если в системе имеется большое количество
объектов разного типа, то каждый тип обеспечивается своим монитором. Если все
мониторы работают с полным доступом, то нет гарантии в том, что монитор в
результате, например, ошибки в нем не воздействует на объект, не
предусмотренный в данной операции.
Наиболее надежным образом защита памяти достигается при помощи изоляции
адресных пространств процессов и мониторов. Если таблицы дескрипторов ресурсов
и сами ресурсы располагаются в отдельных адресных пространствах, то процесс
просто не может получить к ним доступа, а может воздействовать на них только
косвенно, передавая в системном вызове индекс элемента в недоступной для него
таблице. Адресные пространства различных мониторов тоже могут быть изолированы
друг от друга, что при надежной изоляции исключит воздействие ошибки в мониторе
на другие ресурсы.
6.4. Надежные вычислительные системы
Надежность — свойство программной организации структуры системы и многофункционального взаимодействия меж ее ресурсами, при которых обеспечивается неотказное функционирование системы в течение данного времени при сохранении данных характеристик аппаратуры передачи данных и фактически ЭВМ ГОСТ 27.003-83.
Отказ — это такое нарушение работоспособности, когда для ее восстановления требуются определенные деяния обслуживающего персонала по ремонту, подмене и регулировке неисправного элемента, узла, устройства, ЭВМ. С надежностью взаимосвяза
но понятие живучесть — способность программной опции структуры и организации многофункционального взаимодействия меж ее компонентами, при которых отказы либо восстановления всех простых машин не нарушают процесса выполнения параллельных программ сложных задач, а наращивают либо уменьшают время их реализации. Под простой машинкой понимается ЭВМ, дополненная системным устройством.
Для свойства свойства функционирования ВС в теории надежности разработаны
набор интервальных, интегральных и точечных характеристик надежности, также
способы их расчета. Характеристики надежности имеют вероятностный нрав и основываются
на значениях характеристик — интенсивностей отказов составляющих систему
частей.
6.5. Методы аутентификации
Важным элементом любой системы защиты данных является процедура входа в
систему, при которой выполняется аутентификация пользователя. В Windows NT для
вызова диалога входа в систему используется известная комбинация из трех
пальцев — Ctrl+Alt+Del. Как утверждают разработчики, никакая троянская
программа не может перехватить обработку этой комбинации и использовать ее с
целью коллекционирования паролей.
Не хочет ли кто-нибудь попробовать
Система ищет введенное имя пользователя сначала в списке пользователей данного
компьютера, а затем и на других компьютерах текущего домена локальной сети. В
случае, если имя найдено и пароль совпал, система получает доступ к учетной
записи account данного пользователя.
На основании сведений из учетной записи пользователя система формирует
структуру данных, которая называется маркером доступа access token. Маркер
содержит идентификатор пользователя SID, Security IDentifier, идентификаторы
всех групп, в которые включен данный пользователь, а также набор привилегий,
которыми обладает пользователь.
Привилегиями называются права общего характера, не связанные с конкретными
объектами. К числу привилегий, доступных только администратору, относятся,
например, права на установку системного времени, на создание новых
пользователей, на присвоение чужих файлов. Некоторые скромные привилегии обычно
предоставляются всем пользователям например, такие, как право отлаживать процессы,
право получать уведомления об изменениях в файловой системе.
В дальнейшей работе, когда пользователю должен быть предоставлен доступ к
каким-либо защищаемым ресурсам, решение о доступе принимается на основании
информации из маркера доступа.
6.6. Инсайдерские атаки
На сегодняшний день нормой обработки информации в корпоративных приложениях становится работа пользователя на одном и том же компьютере, как с открытой, так и с конфиденциальной информацией, требующих для обработки различной номенклатуры ресурсов. Это существенно расширяет потенциальную возможность хищения нарушения конфиденциальности данных санкционированным пользователем пользователем, допущенным к работе на вычислительном средстве в рамках выполнения своих служебных обязанностей — инсайдером и несанкционированной модификации нарушения доступности и целостности конфиденциальных данных, в результате обработки на том же компьютере открытой информации.
Общий подход к решению задачи защиты.
Из теории защиты информации известно, что эффективная защита может быть построена только на основе реализации разграничительной политики доступа к ресурсам механизмы контроля, в частности контентного контроля, по очевидным причинам могут использоваться лишь как вспомогательные. Однако, как в существующих требованиях к средству защиты, так в известных практических реализациях — в ОС и в приложениях, применение разграничительной политики предполагается для разграничения доступа различных пользователей, допущенных к обработке информации на компьютере, к ресурсам. При реализации же защиты информации от инсайдерских атак, задача реализации разграничительной политики доступа к ресурсам уже иная собственно в своей постановке — необходимо разграничивать режимы обработки различных категорий информации на одном компьютере для одного и того же пользователя а не доступ к ресурсам между различными пользователями. Правильнее здесь уже говорить не о разграничительной, а о разделительной политике доступа к ресурсам. Как следствие, необходимы совершенно иные подходы решению задачи защиты, а механизмами защиты должны выполняться совсем иные требования. Рассмотрим в данной работе возможный апробированный подход к решению задачи защиты и сформулируем требования, реализация которых необходима для эффективного решения задачи защиты от инсайдерских атак.
Поскольку на одном компьютере обрабатывается информация различных уровней конфиденциальности, и при этом обработка информации различных уровней конфиденциальности требует различных ресурсов различные приложения, файловые объекты, устройства, сетевые ресурсы, и т.д., и т.п., причем, как правило, чем ниже уровень конфиденциальности обрабатываемой информации, тем шире номенклатура ресурсов может использоваться при ее обработке что и составляет потенциальную угрозу хищения конфиденциальной информации, задача защиты информации состоит в формировании и изолировании режимов обработки информации различных уровней конфиденциальности.
Формирование режимов обработки категорированной информации состоит в подключении соответствующего набора ресурсов при обработке информации каждого уровня конфиденциальности.
Изолирование режимов обработки категорированной информации состоит в противодействии любой возможности изменения режима обработки санкционированного набора ресурсов информации каждого уровня конфиденциальности.
При реализации подобного подхода уже нечего контролировать, т.к. предотвращается сама возможность хищения конфиденциальной информации, за счет использования несанкционированных не используемых для ее обработки ресурсов.
6.7. Внешние атаки
Атака attack — действие, связанное с несанкционированным доступом в вычислительную сеть и преднамеренным нанесением ущерба как сети в целом, так и любым ее составным частям, включая условия или результаты их функционирования.
6.8. Вредоносные программы
Вредоносная программа на жаргоне антивирусных служб зловред, англ. malware, malicious software — злонамеренное программное обеспечение — любое программное обеспечение, предназначенное для получения несанкционированного доступа к вычислительным ресурсам самой ЭВМ или к информации, хранимой на ЭВМ, с целью несанкционированного владельцем использования ресурсов ЭВМ или причинения вреда нанесения ущерба владельцу информации, иили владельцу ЭВМ, иили владельцу сети ЭВМ, путем копирования, искажения, удаления или подмены информации.
6.9. Троянские кони и вирусы
Троянскими вирусами троянскими конями обычно называют программы, содержащие
скрытый модуль, осуществляющий несанкционированные действия. Эти действия не
обязательно могут быть разрушительными, однако практически всегда направлены во
вред пользователю. В свою очередь, троянские программы можно разделить на
несколько категорий.
Троянские вирусы обычно выполняют или имитируют выполнение какой-нибудь
полезной или экзотической функции. При этом в качестве побочного эффекта они
стирают файлы, разрушают каталоги, форматируют диск и т.д. Иногда
разрушительный код встраивается в какую-нибудь известную программу. Чтобы
привлечь пользователей, полученная троянская программа-вандал часто маскируется
под новую версию данного программного продукта.
Программы, обеспечивающие вход в систему или получение привилегированной
функции режима работы в обход существующей системы полномочий, называют люками
back door. Люки часто оставляются разработчиками соответствующих компонент
операционной системы для того, чтобы завершить тестирование или исправить
какую-то ошибку, но нередко продолжают существовать и после того, как то, для
чего они планировались, завершено или необходимость в нем отпала.
Троянские программы могут также использоваться в целях разведки. К
распространенным программам такого рода относятся программы угадывания паролей.
6.10. Средства зашиты от вредоносных программ
Все знают, что для защиты от вредоносных программ нужно использовать антивирусы. Причиной проникновения вирусов на защищенные антивирусом компьютеры, могут быть разные, например:
· антивирус был отключен пользователем
· антивирусные базы были слишком старые
· были установлены слабые настройки защиты
· вирус использовал технологию заражения, против которой у антивируса не было средств защиты
· вирус попал на компьютер раньше, чем был установлен антивирус, и смог обезвредить антивирусное средство
· это был новый вирус, для которого еще не были выпущены антивирусные базы
Однако, в большинстве случаев, наличие установленного антивируса, может оказаться недостаточно для полноценной защиты, и что нужно использовать дополнительные методы. Из-за неправильного использования антивируса, недостатка самого антивируса и работой производителя антивируса, методы защиты можно разделить на два типа — организационные и технические.
Организационные методы направлены на пользователя компьютера, и направлены на то, чтобы изменить поведение пользователя, ведь не секрет, что часто вредоносные программы попадают на компьютер из-за необдуманных действий пользователя. Например: разработка правил работы за компьютером, которые должны соблюдать все пользователи.
Технические методы направлены на изменения в компьютерной системе, и заключаются в использовании дополнительных средств защиты, которые расширяют и дополняют возможности антивирусных программ. Такими средствами защиты могут быть:
· брандмауэры — программы, защищающие от атак по сети
· средства борьбы со спамом
· исправления, устраняющие дыры в операционной системе, через которые могут проникать вирусы.
1 трекбол — специальный шарик, который в переносных компьютерах NoteBook
размещается рядом с клавиатурой, прокручивается пальцами и служит для
перемещения указателя мыши. В настоящее время гораздо чаще используют
устройство, чувствительное к касанию touchpad. С помощью такого устройства
пользователь управляет указателем мыши, перемещая палец по специальной
поверхности.
—————————————————————————————————————